
/
Case Study
The file processing models Finch and Lark, as well as the ai-coustics API, are now discontinued. If you're building real-time solutions, check out our voice AI model family Quail, or human communication enhancer Rook through the Developer Platform. In case of further questions, don't hesitate to contact us.
We’re delighted to announce the launch of Finch 2 - the next generation of our signature voice isolation model. An upgrade and improvement on our previous Finch model, Finch 2 is now available across our API and web app. With state-of-the-art improvements in clarity, robustness, and realism, Finch 2 sets a new standard for subtractive speech enhancement.
Key takeaways
Finch 2 replaces our legacy Finch model with improved denoising and de-reverb, and other exciting new upgrades
Along with technical boosts, Finch 2 is also more energy-efficient
Finch 2 pairs well with our existing Lark model for a full suite of audio enhancement tools.
What’s new in Finch 2?
Finch 2 replaces our legacy Finch model with substantial upgrades across the board. Here’s what you can expect:
Improved de-noising and de-reverberation
More robust in adverse conditions, including loud noise, strong reverb, speaker to mic distance and more
A more natural sound with better preservation of speaker identity
Significantly less AI processing artifacts
Reduced size, with faster inference and less electricity consumption
Like the original Finch model, Finch 2 is a subtractive model. That means that it removes information from an audio signal. For example, if there’s a lot of background noise, a subtractive machine learning model can help remove the irrelevant information from the signal. So you’ll get the speech of the person you’re interviewing, but not someone coughing or a car going past behind you. We also have a reconstructive model called Lark, which is still available as usual in the API and web app. A reconstructive model is based on generative AI and doesn’t just subtract unwanted audio; it also repairs wanted audio to improve it. When a signal gets too mixed (i.e. a car horn over your interviewee’s voice), it can use its machine learning database to reconstruct what your interviewee was saying exactly, in their own voice
How does it compare to other voice-isolation tools?
We benchmarked our Finch 2 model against other leading tools using the widely recognized DAPS dataset. The results speak for themselves:
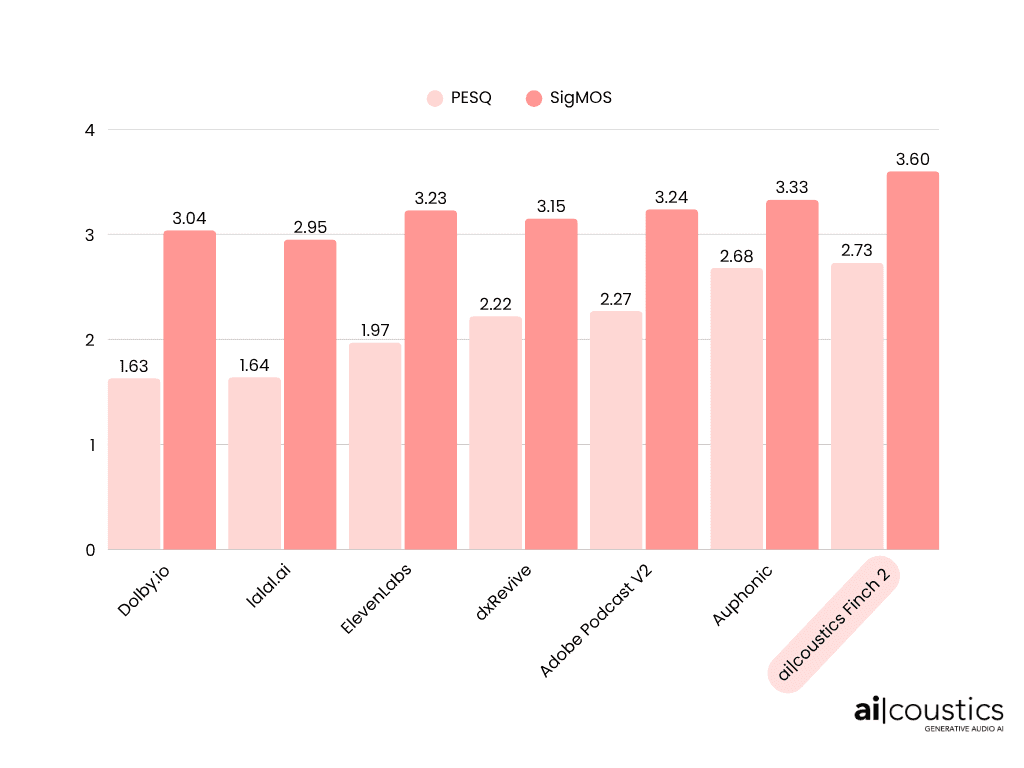
The DAPS (Device and Produced Speech) dataset is an open-source benchmark designed to test how well speech enhancement models can transform real-world, noisy and reverberant recordings into clean speech.
We evaluate each model using two industry-standard metrics:
PESQ (Perceptual Evaluation of Speech Quality) Measures how closely the enhanced audio matches the original clean reference.
SigMOS (Signal Mean Opinion Score) A no-reference metric that simulates human subjective listening tests - it measures perceived quality, not just similarity to the original and Finch 2 comes in first place
Should I use Finch 2 or Lark?
Finch 2 and Lark are powerful audio enhancement models ideal for different contexts.
Choose Finch 2 if:
Your voice recording is already good, and you just want to isolate it, for example separating a voice track from a movie or song
You’ve recorded in tough conditions with very strong background noise, lots of reverb, distant speakers and more
Your first priority is preserving the sound of the original voice
Choose Lark if:
You want to restore an old recording to make it sound like it was recorded with modern studio equipment
You want to add back high frequencies in bandwidth limited recordings
You want to fix strong compression, for example in Zoom or phone call recordings
You want to create a full and professional sound for your voice
Still can’t decide? The good news is you can test out both models in our Developer Portal, right now.
