/
Case Study
Building Voice Agents? If you're looking to optimize audio for downstream systems such as ASR and VAD, use the machine-targeted Quail model family. See more in our docs.
Today, we’re introducing Rook - our most compact and efficient model yet, purpose-built for real-time and streaming speech enhancement.
Rook delivers exceptional speech clarity and natural sound, even in the most resource-constrained applications, using less than 1% of the processing power of our flagship models. This makes it possible for teams to build offline-first, low-latency products that previously required cloud processing.
Rook is ideal for live conferencing, voice AI agents, communication, audio devices, streaming, broadcast technology, and privacy-sensitive environments.
Solving the challenges of real-time on-device enhancement
Enhancing speech in real-time and on audio devices comes with two major constraints:
Low-latency processing: Applications like digital communication and AI voice agents require low-latency processing. Where a cloud model can process audio with the context of the full file, a real-time model must enhance audio in short frames as it arrives. This imposes strict latency and design trade-offs.
Model capacity: The models must be small enough to run efficiently on devices such as laptops, phones, or smart speakers. This means it’s difficult to match the power and accuracy of large-scale cloud models.
These constraints make it significantly harder to deliver natural, high-quality results in real-time scenarios, but we’re bridging the gap.
Introducing Rook: optimized for naturalness and efficiency
Rook is a new family of models designed specifically for real-time speech enhancement on audio devices and for streaming applications. It is available in two sizes:
Rook-S (small)
Rook-L (large)
These variants represent different trade-offs between sound quality and compute requirements. The architecture is flexible for your performance needs and latency goals.
Building Rook, we focused on three key innovations to overcome typical real-time device and streaming processing challenges:
Focusing on what really matters
Rook models isolate your voice from dynamic noise environments and remove late reverberation. This results in improved intelligibility while preserving the natural quality of speech.
Realistic training conditions
Instead of relying on unrealistic and overly aggressive data augmentation, we trained Rook using natural noise profiles such as wind and real room acoustics, resulting in models that generalize better to real-world conditions. The result? Rook thrives in everyday recording environments.Tailor-made for efficient deployment
Our Rook models use a highly optimized neural architecture ideal for streaming applications and fitting even the tightest compute budgets typical of audio hardware.
Understanding Rook in context
How does Rook compare to other real-time and streaming speech enhancement tools? We benchmarked Rook against other leading tools using the widely recognized DAPS dataset:
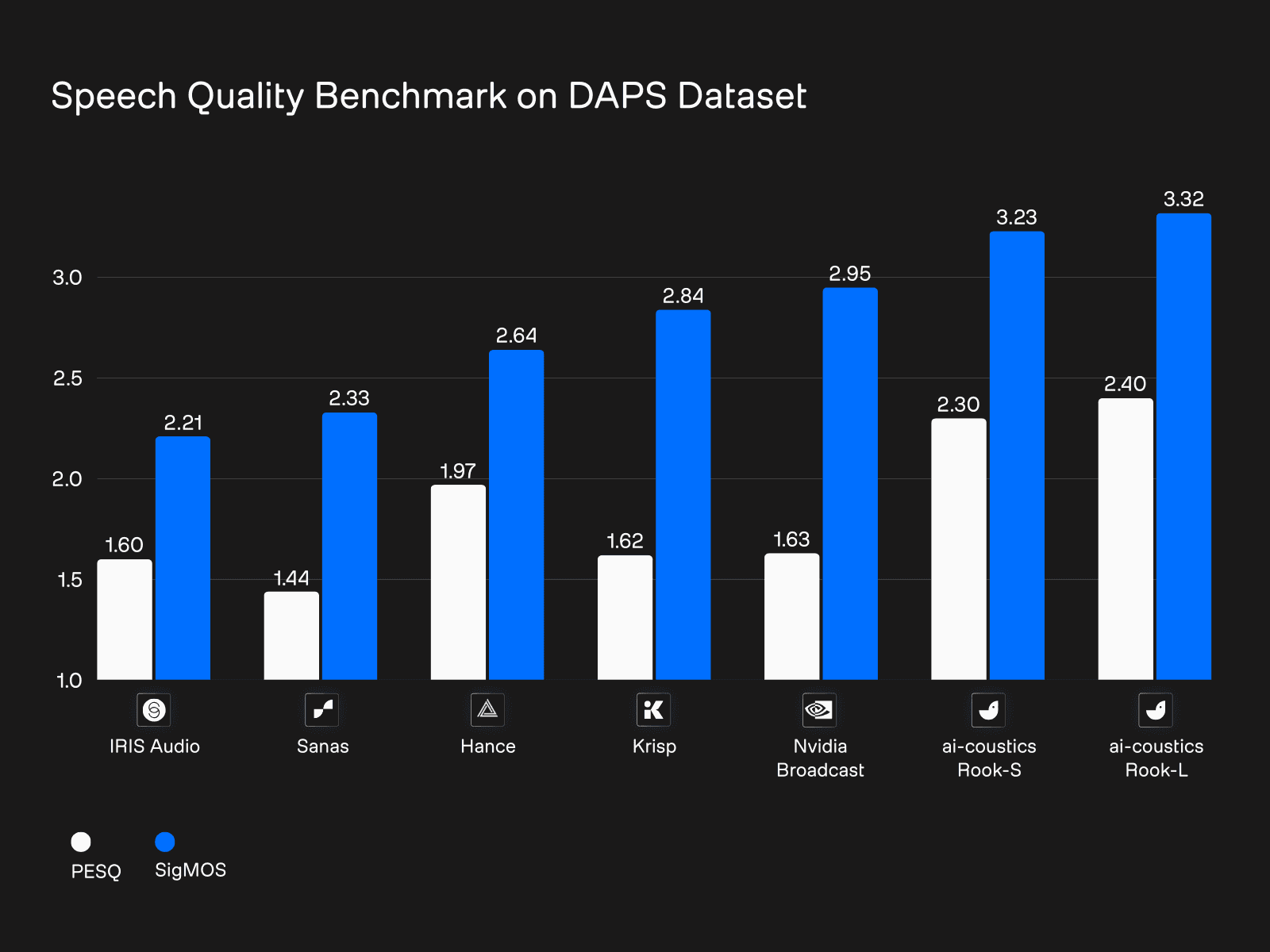
The DAPS (Device and Produced Speech) dataset serves as a publicly available benchmark to assess how effectively speech enhancement models can convert real-world recordings—often affected by noise and reverberation—into clean speech.
To measure model performance, we use two widely accepted industry metrics:
PESQ: Measures how closely the enhanced audio matches the original clean reference.
SIGMOS: A no-reference metric that simulates human subjective listening tests – it measures perceived quality, not just similarity to the original.
Rook performs better than all competitors on both of these metrics.
Let’s get technical: Rook’s highlights
Rook offers users:
Real-time processing at 48 kHz with latency as low as 30ms
High quality speech at only 0.35 GMACs/sec (Sparrow-S) and 1.2 GMACs/sec (Rook-L), fitting even the tightest compute budgets
Significantly reduced distortion and over-suppression of speech segments compared to other real-time models
Robust performance, especially in dynamic noise environments, different room types, and geometries
Configurable architecture to meet specific quality, size, or latency constraints
Easy and lightweight deployment through the ai-coustics SDK for embedded, mobile, desktop and cloud environments
Unlock real-time speech enhancement with Rook
Rook represents our commitment to making speech enhancement universally accessible - with natural quality, ultra-low latency, and deployment flexibility.
Stay tuned for more technical insights in the next weeks and for the upcoming release of "Airten", our specialized audio machine learning inference engine, which will make our Rook models even faster.
