
Announcing Lark 2: the next generation of reconstructive speech enhancement
Jul 29, 2025
/
Fans of Lark, rejoice: Lark 2 is here. Bolder, better, and stronger than ever, Lark 2 is our most advanced reconstructive speech enhancement model yet.
Lark 2, like its predecessor, is built with our speciality reconstructive AI technology which goes beyond just isolating speech to repair existing speech and restore lost information – all while preserving the authentic human voice at the heart of your audio.
Let’s dive into the details.
What is Lark 2?
Lark 2, the latest iteration of our flagship speech enhancement model, is now accessible through the ai-coustics API and SDK. Lark 2 enhances recordings in any language to achieve studio-quality sound, even if they contain the following imperfections:
Background noise
Wind and handling noise
Room reverb
Clipping and distortion
Cheap microphone (mobile phones, old recordings, etc)
Codec compression (from phone and video calls)
Band limitation and low sample rates
Packet loss
And more!
Along the way, Lark 2 keeps your audio content, prosody, and speaker identity intact.
From Lark to Lark 2: key improvements
We already received great feedback for Lark. But at ai-coustics, we’re always keen to keep iterating and improving. One key difference between the two models is the amount of data we’ve trained Lark 2 on. It’s got many more hours, samples, and styles of data under its belt, with some pretty powerful results.
Here are the key differentiators:
Cleaner voice isolation: One main goal of our Lark models is to separate speech from the rest of the audio – Lark 2 does this more effectively, with better denoising and reverb removal.
Robust and resilient: The world is noisy, with complex audio situations. Lark 2 handles it even better than our original model, and is ideal for complex combinations of real world distortions.
Improved performance on compressed audio: Lark 2 enhances recordings from phone calls, Zoom meetings and the like with ease.
Anti-hallucination: Lark 2 is specially trained against audio hallucinations, including “ghost voices” and similar AI mistakes. Ensure you have clean and coherent audio with Lark 2.
What does this mean for you?
Automate workflows without manual editing or listening over enhanced samples
Better data for downstream tasks like voice cloning or AI training
No manual DAW edits
How does Lark 2 compare to other speech enhancement tools?
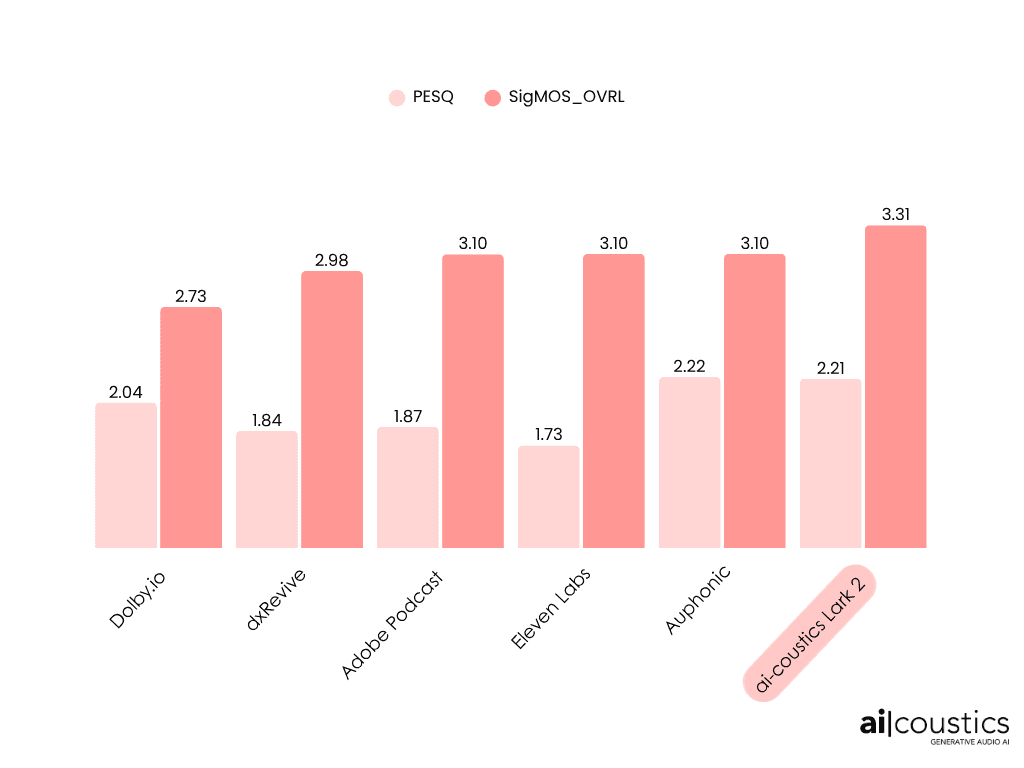
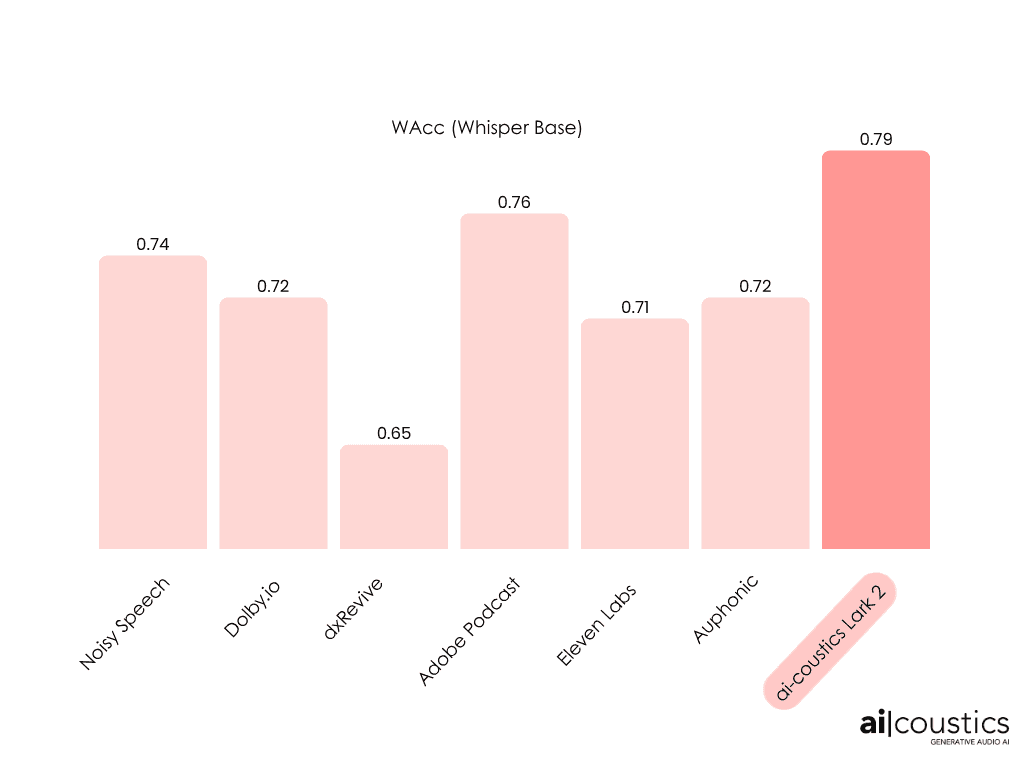
We benchmarked Lark 2 against other leading tools using the Dolby Universe validation data set. This dataset serves as a publicly available benchmark to assess how effectively speech enhancement models can convert recordings that are affected by several audio degradations at once back into clean speech.
To measure model performance, we use three widely accepted metrics:
PESQ: Measures how closely the enhanced audio matches the original clean reference.
SIGMOS: A no-reference metric that simulates human subjective listening tests – it measures perceived quality, not just similarity to the original.
WAcc: Word accuracy measures how well a downstream speech-to-text model, in this case Whisper Base, can transcribe the audio after enhancement.
Lark performs on-par or better than all competitors across all of these metrics.
Built for developers, producers, software and more
Whether you’re working in Voice AI or broadcasting, content creation or digital communications – Lark 2 is the ideal tool to create a stronger, more engaging product.
Lark 2 is now available across ai-coustics API and SDK.
Ready to get started? Reach out for your personalized demo today, or sign up to our API.
