
Meet Quail Voice Focus: Primary speaker isolation in real-time
Dec 9, 2025
/
Real-world audio rarely behaves the way AI systems expect. A second voice enters in the background, a nearby conversation bleeds into the signal, or speech from a TV slips through. Add to that the usual challenges of background noise, reverberation, and low-quality microphones – all of which reduce intelligibility.
These conditions are perfectly normal in human environments, but they break many of the assumptions that real-time voice AI systems depend on.
Relying on traditional speech enhancement models in these situations comes with two major drawbacks:
They enhance all voices in the signal instead of only the main speaker.
Perceptual enhancement models are built for human ears, not to improve Speech-to-Text (STT) systems. By removing subtle phonetic detail, they often make transcripts less accurate even when the audio sounds cleaner.
Quail Voice Focus solves these issues. It isolates the foreground speaker, suppresses competing voices, and keeps the acoustic cues required for reliable transcription.
Foreground-first speech enhancement
Quail Voice Focus is our new real-time speech enhancement model, purpose-built to isolate and elevate the foreground speaker while suppressing both interfering speech and background noise.
Like the original Quail, this model isn't tuned for perceptual audio quality. Its priority is preserving the machine-relevant phonetic structure that speech-to-text systems require. Optimizing for STT clarity can actively degrade how audio sounds to a human ear, and this model may sound worse as a result. That's the trade-off between sounding good and delivering cleaner, more reliable input for downstream STT models.
Example 1
Example 2
Foreground-first speech enhancement
Example with Raw Audio
Yeah, no problem.
It's a little bit pitched.
Yep.
Yeah. And do
you guys have...
Yep.
Three.
Example with Quail Voice Focus
Yeah, no problem.
It's a little bit pitched.
Yep.
Yep.
Three.
Red means wrong insertions
Transcribed by Gladia
Key benefits
Improved turn taking: Secondary voices are suppressed and won’t falsely trigger the VAD and STT models.
No insertions from interfering speakers: no insertions in the main speaker transcript from interfering speakers,background media devices, or echo.
Improved STT accuracy for the main speaker: Reduces substitutions, insertions, and deletions that arise from competing speech and low signal-to-noise ratios.
Language agnostic: No language specific model necessary.
Low-latency, production-ready: Lightweight architecture optimized for real-time CPU workloads.
All-in-one SDK: Models for perceptual SE, STT optimised SE and Voice Activity Detection (VAD) – all delivered through a fast, lightweight Rust SDK.
Understanding STT Errors: Substitutions, Insertions and Deletions
Before comparing providers, it’s useful to break down the three main components of Word Error Rate (WER). Each error type highlights a different weakness in a speech-to-text system, offering insight into why mistakes occur, not just how many. In the visualisations below, bars are divided into the following categories:
Substitutions
A substitution happens when the model recognises that a word was spoken but outputs the wrong one. For example, transcribing “meeting” as “eating”. These errors typically stem from phonetic overlap: background noise, echo or competing speech smudge the acoustic detail, leading the model to confuse similar-sounding words.
Insertions
An insertion occurs when the model adds a word that never appeared in the audio. For instance, converting “Turn left here” into “Turn left right here”. Insertions often signal a tendency to hallucinate: the model relies too heavily on linguistic patterns when the audio is unclear, filling gaps based on expectation rather than evidence. Another common source of insertions is when words get picked up from interfering speakers or media devices running in the background.
Deletions
A deletion is when the model omits a spoken word altogether, for example, turning “The package arrived today” into “The package arrived”. These errors often occur when parts of the signal are obscured by noise such as wind bursts, clipping or microphone bumps. Models with weaker noise resilience prefer to drop uncertain words rather than attempt a guess.
Provider-level insights: What the benchmarks reveal
With these error modes in mind, we can now examine how today’s commercial transcription engines behave under real-world conditions. The graphs below compare WERs across five major STT providers: Deepgram, Cartesia, Gladia, AssemblyAI and ElevenLabs – on our internal benchmark dataset.
This dataset was recorded in the wild with the specific challenge for foreground speech enhancement in mind. It contains several hours of audio with a foreground speaker and one or several background speakers or media devices in the background. It combines this with challenging real-world conditions, i.e., combinations of diverse noises, rooms, recording devices, and transmission chains.
For each STT provider we compare the raw audio without any preprocessing vs. the audio with Quail Voice Focus pre-processing:
WERs on internal dataset (English)
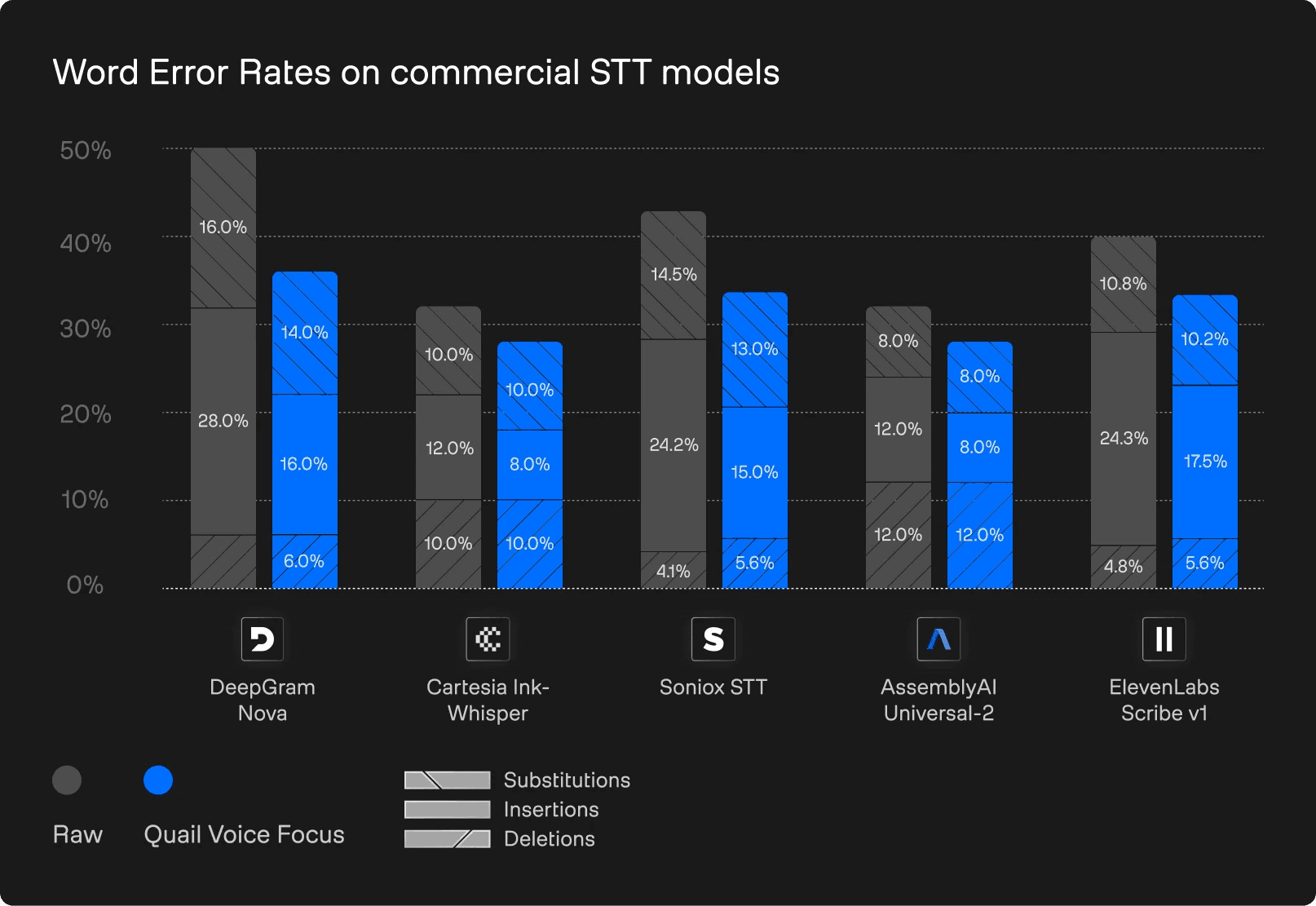
While all providers differ in absolute level of WER they all suffer from a high level of insertions triggered by side chatter.
Built for real-world environments
Quail Voice Focus is engineered for the places where people actually talk – busy public settings, shared homes and offices, media-heavy spaces, and moments when conversations naturally overlap. By locking onto the primary speaker and suppressing competing voices, it delivers consistently clear audio even in challenging conditions.
It also brings an added benefit: privacy awareness. By preventing background voices from being unintentionally surfaced or transcribed, Voice Focus helps minimise accidental capture of conversations that were never meant for the microphone.
The result is a powerful front-end for voice agents, STT pipelines, communication tools, meeting platforms and embedded systems that perform reliably in the real-word.
Try the ai-coustics SDK today
Voice Focus is available now in the ai-coustics SDK. Test it here for free, watch this quick tutorial on how to get started, or get in touch with our team for more information.
