
Written by
Tim Janke
,
Head of Machine Learning
Research
/
We talk about Word Error Rate a lot. It’s one of our key metrics in developing and launching new audio enhancement models to improve Voice AI performance. In particular, WER makes a massive difference when it comes to evaluating performance for Speech-to-Text (STT) systems, against a more perceptual quality evaluation like the PESQ and SigMOS methodologies. But what exactly is Word Error Rate, and why is it so important? Let’s break it down.
What is Word Error Rate?
Word Error Rate (WER) measures how accurately your Automatic Speech Recognition (ASR) system is performing. It does so very simply, by calculating how many words your ASR correctly parsed. Here’s the formula:

To measure the WER, we combine the number of Substitutions (S), Deletions (D), and Insertions (I), divided by the Number of Words (N).
So let’s say your user has said “I sent the file” (a four-word sentence) and your ASR system understands this as “I sent a file” – a fairly common error, because articles often sound similar in natural speech, so an ASR system can struggle with them. But still an error! Here’s how we calculate the WER:
Substitutions (S): 1 (“a” instead of “the”)
Deletions (D): 0
Insertions (I): 0
Number of words in the reference sentence (N): 4
WER = 1 ÷ 4 = 25%
The lower the Word Error Rate, the better.
Why is Word Error Rate important?
Word Error Rate is particularly important when you’re looking at STT systems, even (or especially!) STT systems that are not seen by the user as STT. For example, many voice agents use an in-built STT transcription system to understand what the user is asking for, and then respond. The pipeline is voice-to-text-to-voice, instead of voice-to-voice, as the end user might understand it. That means that your ASR process has to perform at a very high level, in order for your voice agent to receive the user’s actual prompt and respond correctly.
Word Error Rate can also impact the flow of conversation, particularly if it misinterprets a cue or trigger. And of course, when it goes wrong, it can lead to disastrous results. The example we used above (“a” instead of “the”) is pretty benign, but what if your user said “don’t share this publicly” and your ASR understood “share this publicly”? A small increase in WER accuracy has a massive impact on a user’s perceived performance of your voice agent.
It’s also one of the most important metrics when we’re talking about speech enhancement in STT. Using perceptual enhancement tools (models that are built for human ears) can actually make your ASR perform worse. For example, when we tested the popular preprocessing audio perception tool Krisp against German and English audio samples, it made the WER worse in all cases for German and in three out of five cases for English.
That means that using a tool that shows a high reduction in WER is a more accurate metric for voice agent success than simply a tool that “sounds nice” to human ears.
How do we use Word Error Rate at ai-coustics?
Word Error Rate is the primary evaluation metric we use to measure how our SDK model Quail improves ASR and STT systems in real-world conditions. While we use a range of metrics to assess and understand our model performance, we find that WER is most useful when you’re optimizing for functional quality, instead of perceptual quality.
Perceptual quality of course has its place, and we have models designed specifically for human ears. But for voice agents and other Voice AI tools, WER minimizes STT and ASR errors that break downstream systems.
Here’re the major places we use WER.
Training and evaluation
Training is crucial to building our robust models with their real-world efficacy. Too often, voice agents and other Voice AI tools are trained in pristine lab conditions – nothing like the real world, with its chaotic acoustic conditions featuring everything from background noise to other speakers to room reverb to poor quality microphones and more.
In contrast, we train our models on hundreds of hours of chaotic, messy, real-world audio, to ensure that your voice agent can perform even in the most challenging circumstances. And we measure the success of those models with Word Error Rate, optimizing and enhancing each solution until we see evidence of big changes and improvements. We focus on relative WER reduction to demonstrate model robustness across diverse acoustic scenarios. Before we launch any new model, we measure to ensure it has an actual impact on WER — for example, Quail reduces WER by 15-35% depending on provider and noise type.
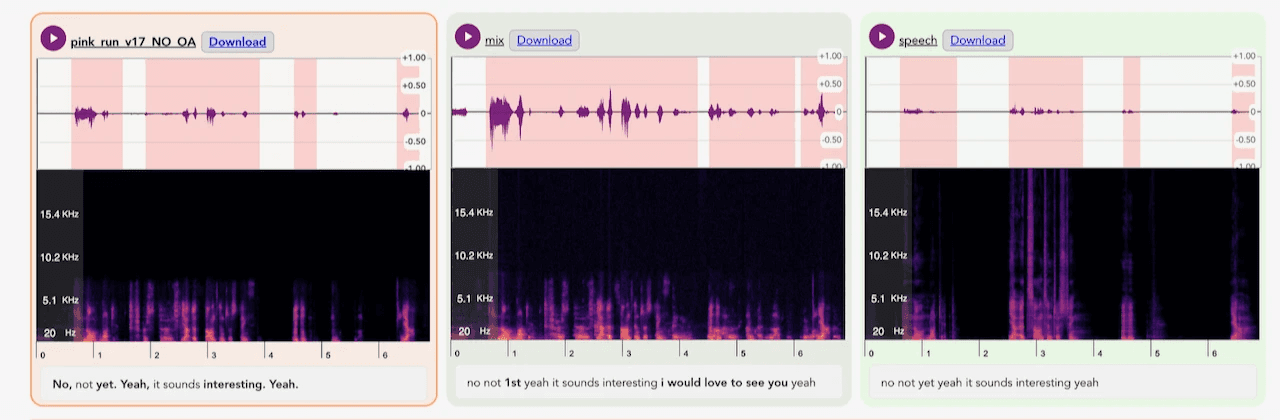

Example of how enhanced samples are being compared with clean and noisy audio to determine the impact on transcription accuracy.
Communication
Much of the conversation around Voice AI still evaluates audio through a human lens, whether it sounds clean or natural. That framing makes sense for human-facing audio applications (as in our evaluation of Rook), but it misses the mark for voice agent pipelines. In this context, audio enhancement is not about improving perceived quality for people, and perceptual metrics like PESQ or SigMOS are poor indicators of success.
The real objective is machine intelligibility. Word Error Rate (WER) provides a far more meaningful signal: when enhancement reduces WER, it improves the reliability of ASR and downstream agent behavior, even if the audio does not score higher on human perceptual metrics.
That’s why we let developers test ai-coustics models on their own data, so they can measure WER improvements, assess ROI, and evaluate production readiness for their specific Voice AI use case.
See how reduced WER impacts your voice agent
Our specialized SDK models (nesting under the Quail family) all work to reduce WER and therefore boost your ASR system’s performance. Check out our guide to getting started with the ai-coustics SDK, or jump right into the Developer Platform.
