

Written by
Tim Janke
,
Head of Machine Learning
Product
/
Voice Activity Detection (VAD) is a critical part of any real-time voice pipeline. It determines when speech is present, when a turn starts, and when audio should be passed to downstream models.
When VAD is unreliable, the entire experience suffers. Speech can be missed, turns can feel unnatural, and voice agents may respond too early, too late, or not at all.
That is why we developed Quail VAD 2.0: a lightweight, modular VAD model built for robust real-time speech detection in challenging acoustic environments. Unlike the previous VAD functionality in the ai-coustics SDK, which was integrated into our speech enhancement models, Quail VAD 2.0 is purpose-built for speech activity detection and can be used independently or together with the rest of the Quail audio stack.
Built for real-world audio
Production audio is rarely clean. Voice AI systems need to handle background noise, reverberation, echo, compression artifacts, distortion, low-quality microphones, music, far-field speech, and rapidly changing environments.
Imagine someone calling your agent from a train, or a customer ordering at a drive-through kiosk next to a busy road.
Quail VAD 2.0 is designed for these conditions. It provides reliable voice activity detection even when the input signal is noisy or degraded, helping real-time systems stay responsive and accurate in everyday deployment scenarios.
Integrated directly into the ai-coustics SDK
Quail VAD 2.0 runs natively inside the ai-coustics SDK through AirTen, our lightweight inference engine.
Developers can add robust speech detection without introducing a separate runtime, model format, or inference stack. VAD and speech enhancement can run within the same SDK, making deployment simpler while keeping latency and compute overhead low.
For teams building voice agents, live communication tools, or streaming applications, this means fewer moving parts and a more reliable real-time audio pipeline.
Key benefits
Reliable speech detection: Accurately identifies voice activity in noisy, distorted, and reverberant environments.
Low latency and lightweight compute: Designed for real-time applications with minimal processing overhead.
Native SDK integration: Runs directly in the ai-coustics SDK through AirTen, with no additional inference runtime like ONNX required.
Flexible: Use raw probability values to implement custom smoothing and thresholding logic, or rely on the integrated post-processing layer and tune it to your stack.
Modular audio processing: Combine Quail VAD 2.0 with Quail Voice Focus for primary speaker isolation and speech activity detection in multi-talker environments.
Performance in challenging conditions
We evaluated Quail VAD 2.0 against the widely used SileroVAD on an internal benchmark of challenging real-world speech detection scenarios.
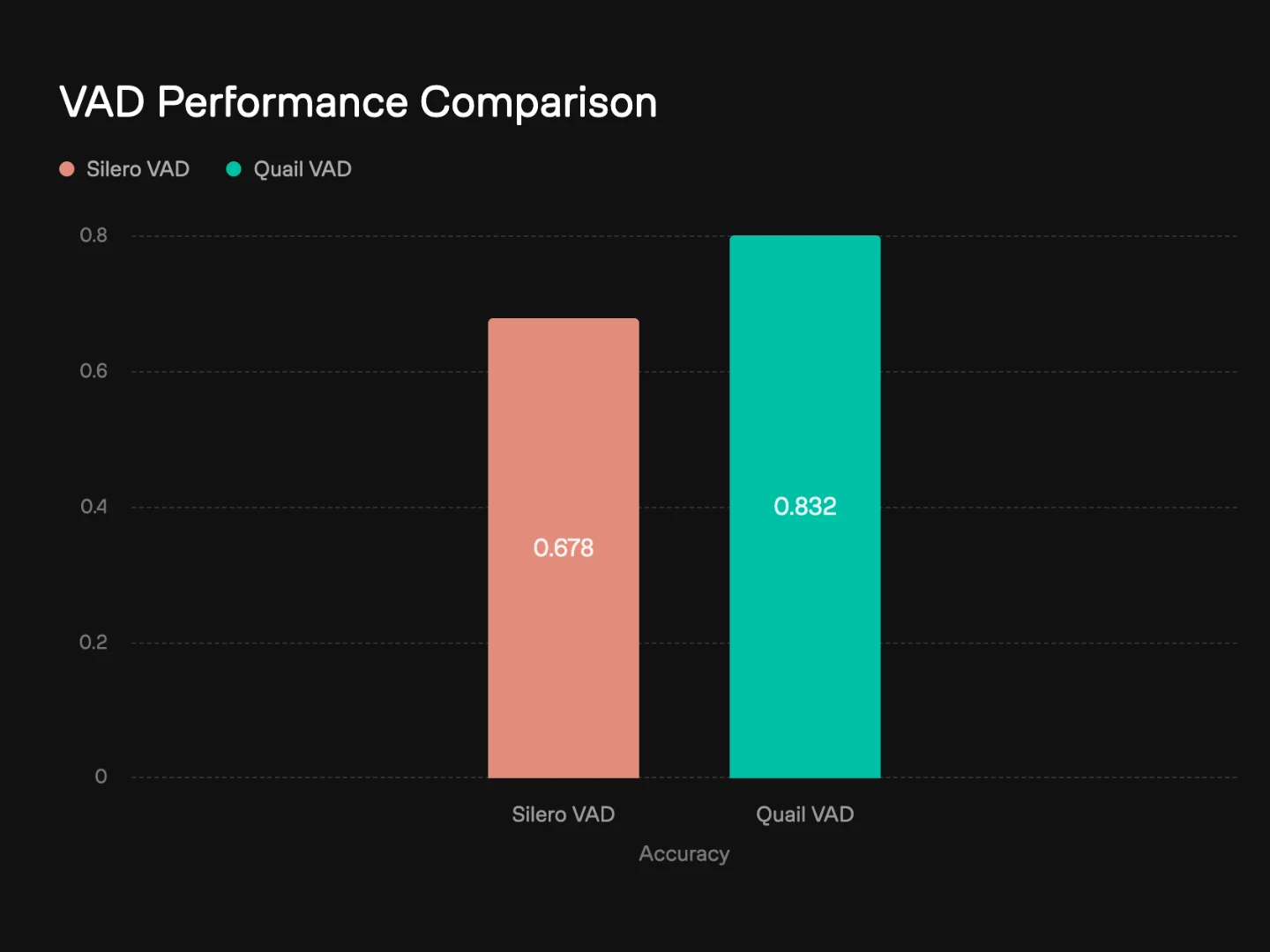
In clean and controlled audio, modern VAD systems often perform well. The real difference appears in challenging acoustic conditions, where noise, distortion, and reverberation can lead to missed speech segments.
Quail VAD 2.0 is designed to reduce these failure modes and provide stable speech detection in the kinds of environments where real voice applications operate.

What this means for your voice application
With Quail VAD 2.0, voice systems can detect speech more reliably, route speech segments to ASR more accurately, and support more natural turn-taking behavior.
Because it is integrated directly into the ai-coustics SDK, teams can add robust VAD to their pipeline without increasing deployment complexity.
The result is a simpler, more reliable foundation for real-time voice AI.
Try Quail VAD 2.0 in the ai-coustics SDK
The new Quail VAD 2.0 is now available as part of the ai-coustics SDK.
Book a demo, sign up to our developer platform, or clone the SDK from GitHub to start testing locally.
