
/
Case Study
When deploying voice agents at scale, performance and efficiency are key for any organization. It's the difference between a pipeline that holds up under pressure and one that degrades every time conditions aren't perfect.
Clean audio input is where reliable voice agents start. That’s why we’re launching Quail Voice Focus 2.1, our flagship speaker isolation model rebuilt to be up to 10 times more efficient, while offering better performance than its predecessor.
Why speaker isolation matters
Production voice pipelines have a persistent problem. Without isolation, background speakers and device echo are all treated as intelligible speech. It gets transcribed alongside the primary speaker and corrupts the turn-taking logic, often breaking the agent stack entirely.
Our Quail Voice Focus model is built to fix this at the source by isolating the primary speaker in real-time. As soon as the model recognizes the primary speaker it locks onto the foreground speaker consistently regardless of input loudness, making it one less variable your pipeline needs to account for.
Two new models, built for scale
Today we are releasing Voice Focus 2.1, delivering improved primary speaker isolation at a fraction of the compute:
Voice Focus 2.1 S is 10x smaller than Voice Focus 2.0 and still outperforms it. Built for high call volumes on constrained infrastructure and edge deployments. Choose S for maximum efficiency with a minimal drop in performance.
Voice Focus 2.1 L delivers the best-in-class enhancement quality at 25% lower compute than 2.0. Choose L for best overall performance.
Both models run in real time on CPU with an end-to-end latency of 30ms, work at 8kHz as well as 16 kHz and drop straight into your existing integration.
Improved real-world performance
Real-world audio is messier than most benchmarks capture. Production calls arrive with multiple simultaneous background speakers, media playback, and layered noise, alongside primary speakers across a wide range of languages, accents and loudness levels. The Voice Focus 2.1 training pipeline was built around that reality, with significantly more complex acoustic scenes than previous generations pushing robustness further than ever before.
Quail Voice Focus 2.1 Benchmark
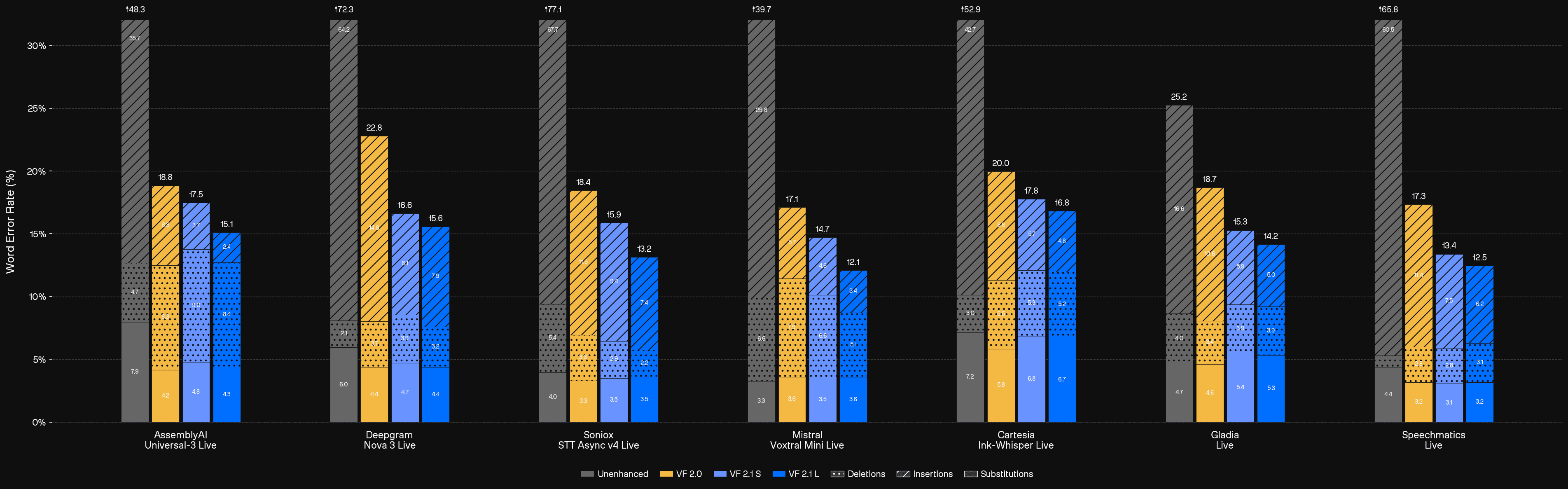
We evaluated Voice Focus 2.1 on a data set that mimics real-world failure cases closely, see this page for a range of qualitative examples.
Processing raw audio leads to a high volume of insertions across all major STT providers, resulting in broken turn-taking and polluted LLM context. Across seven major STT providers, unenhanced audio sits between 25–77% WER.
Voice Focus 2.1 cuts that dramatically, on Speechmatics from 65.8% down to 12.5%, on Cartesia from 52.9% to 16.8%, on AssemblyAI from 48.3% to 15.1%. The gains are consistent across every provider tested, driven by a sharp reduction in insertions with only a marginal increase in deletions.
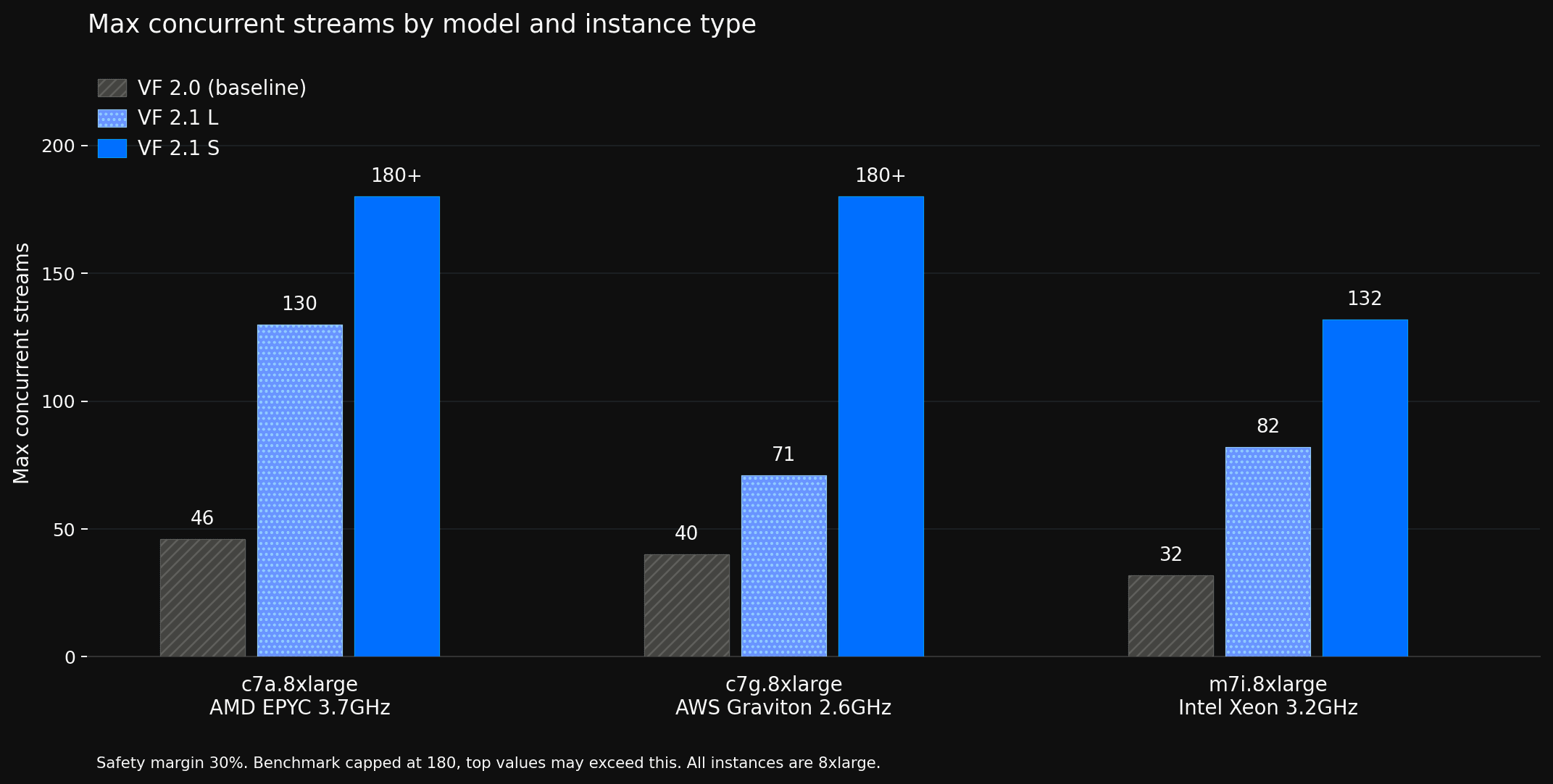
Voice Focus 2.1 S and L deliver up to 10x more concurrent streams at 30% safety margin, tested across three major AWS instance types. As the graph below shows, both models outperform Voice Focus 2.0 while running significantly leaner on CPU.
The result is lower Word Error Rates and stronger VAD performance on the audio that actually shows up in production, for both the built-in Quail VAD and pipelines pairing Voice Focus with external VADs like Silero.
Try Quail Voice Focus 2.1 today
Curious to see how speaker isolation improves your pipeline's performance? Quail Voice Focus 2.1 is available now in the ai-coustics SDK.
Test it for free in less than 2 minutes on our developer platform, or dive straight into the documentation to get started.
