

Written by
Fabian Seipel
,
CEO and Co-founder
Product
/
Millions of voice interactions happen between humans and machines every day, but the gap between what's said and what's heard is wider than most teams realize. As agent deployment accelerates, one problem keeps surfacing: real-world audio is messy and most Voice AI pipelines aren't built for it.
Today we're launching two updates that directly address this.
Quail Voice Focus 2.0: the latest iteration of our speaker isolation model, delivering cleaner, reliable speech separation in real-world conditions.
And a native LiveKit integration: bringing the full ai-coustics stack into the most widely used real-time infrastructure layer for voice agents in production.
Together, they move us closer to a world where audio intelligence is built into every voice agent stack by default.
The problem starts before the LLM
Here's something counterintuitive: voice agents don't usually fail because they can't hear, they fail because they hear too much. They get deployed into homes, offices and clinical environments, all with competing audio. Interfering speech is one of the most common failure modes, triggering VAD, bleeding into the transcript and injecting the wrong context into the language model.
The instinctive fix is to use noise cancellation tools, but perceptual enhancers introduce two fundamental problems. First, they enhance all voices in the signal instead of isolating the primary speaker. Second, they are optimized for how audio sounds to human listeners rather than how speech-to-text systems interpret it. By stripping phonetic detail, these tools trade transcription accuracy for the illusion of cleaner audio.
Quail Voice Focus 2.0
Quail Voice Focus 2.0 is designed to solve this problem at the source by isolating the foreground speaker before audio reaches ASR. It's inspired by the cocktail party effect, the innate human ability to focus on a single voice in a noisy environment. We bring that capability to machines, but adjust it to ensure that only the main speaker is in focus.
Foreground isolation is a selection problem under acoustic ambiguity. The system has to determine which speech belongs to the primary interaction and which doesn't, modeling spatial distance, room acoustics, device coloration, temporal overlap and echo behavior simultaneously. The foreground speaker must remain intact while interfering speech, echo and background activity are attenuated without introducing artifacts.
Beyond isolation, it handles denoising, dereverberation and codec artifact repair in a single pass, making it robust across the full range of conditions voice agents face in production.
Additionally, the Quail Voice Focus model comes with natively integrated Voice Activity Detection (VAD).
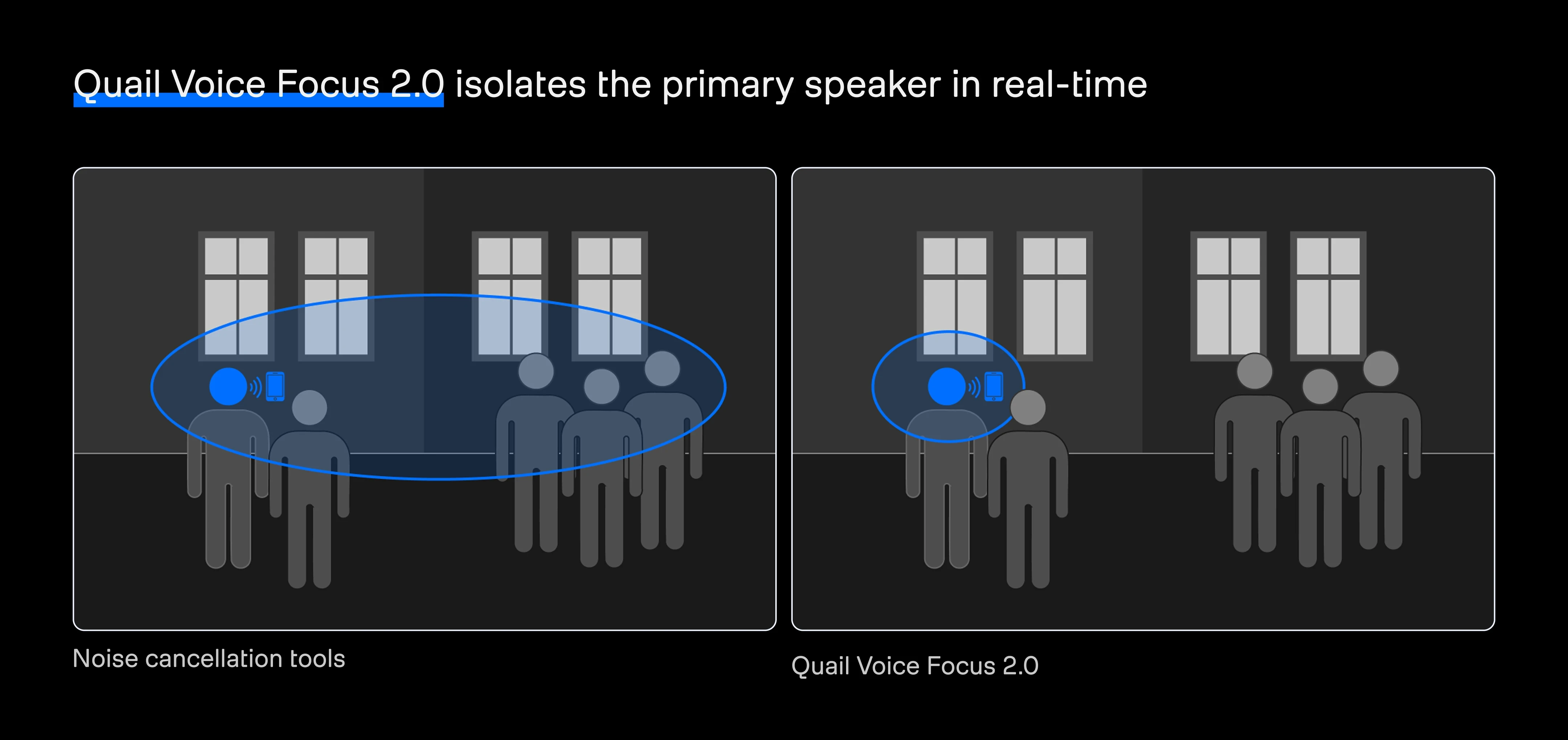
Quail Voice Focus 2.0 in examples
How Quail Voice Focus 2.0 was trained
Rather than relying on generic augmentation, the model is trained on semi-synthetic audio built around real voice-agent failure modes: near-field speech, competing speakers, device playback, environmental noise and echo-aligned signals in simulated rooms. In other words, the conditions that actually break production pipelines. You can read about the process in more detail in our technical deep-dive blog.
To evaluate performance, we're also open-sourcing Dawn Chorus, a dataset of 450 real-world recordings designed to test foreground speaker isolation, with clean foreground references and transcripts for each example.

Benchmark highlights
We benchmarked Quail Voice Focus 2.0 across major commercial STT providers including Assembly, Cartesia, Deepgram, Gladia, Mistral, Soniox, and Speechmatics using the Dawn Chorus dataset.
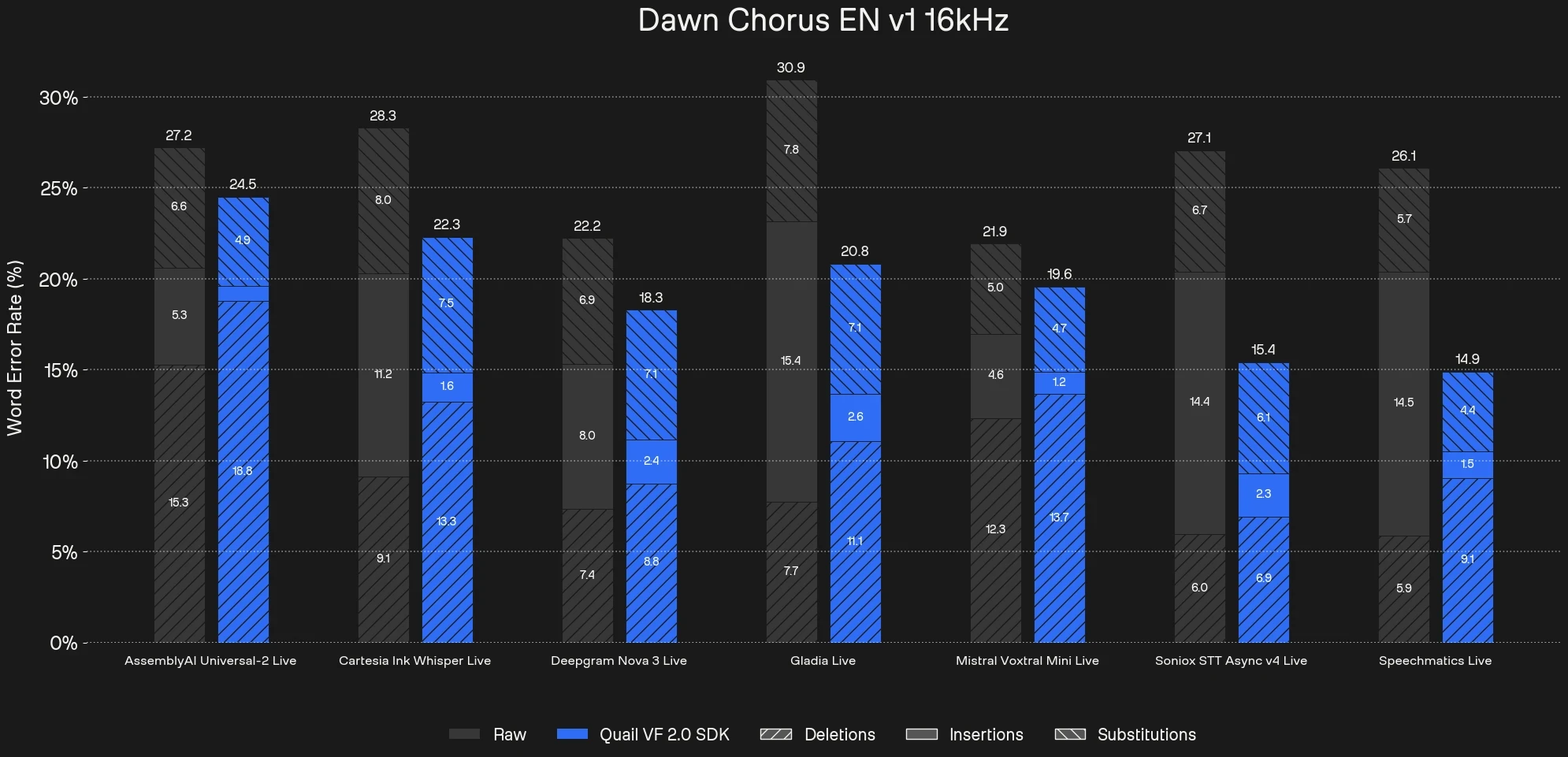
The impact is consistent across providers:
10-43% reduction in Word Error Rate under real-world conditions
Insertions drop sharply as background voices are suppressed before reaching ASR
Substitutions and deletions remain stable, meaning primary speaker fidelity is preserved
You can explore the full benchmark results for Voice Focus 2.0 here.
Tuning the enhancement level to your stack
No single operating point works across every stack. That's why Quail Voice Focus 2.0 comes with a configurable enhancement level parameter, giving you direct control over suppression aggressiveness for your specific ASR backend. Dial it up for noisy environments, dial it back where over-filtering is the bigger risk.
In the technical deep-dive we go deeper on how the insertion/deletion tradeoff shifts across different STT providers, how to find your optimal operating point, and the training methodology behind the model. It's full of the technical detail you need to make the right decisions for your pipeline.
Native in LiveKit
We're also announcing a native integration with LiveKit, one of the most widely used real-time infrastructure layers for production voice agents. Developers already building on LiveKit now have ai-coustics audio intelligence available natively, with minimal setup.
"By integrating ai-coustics' Voice Focus model into LiveKit Agents, we're bringing a leading ASR-optimized speech enhancement and primary speaker isolation to developers. Unlike traditional noise suppression tuned for human ears, this model preserves critical phonetic and timing cues essential for downstream STT accuracy. It enables voice agents to reliably understand users in noisy, multi-speaker environments."
David Zhao, Co-Founder, LiveKit
The full ai-coustics stack now runs natively inside the framework. That means Quail, our flagship machine-optimized speech enhancement model built for single-speaker environments, processes and cleans audio before it ever reaches ASR. For multi-speaker scenarios, Quail Voice Focus 2.0 adds foreground speaker isolation with integrated VAD, ensuring only the right voice comes through.
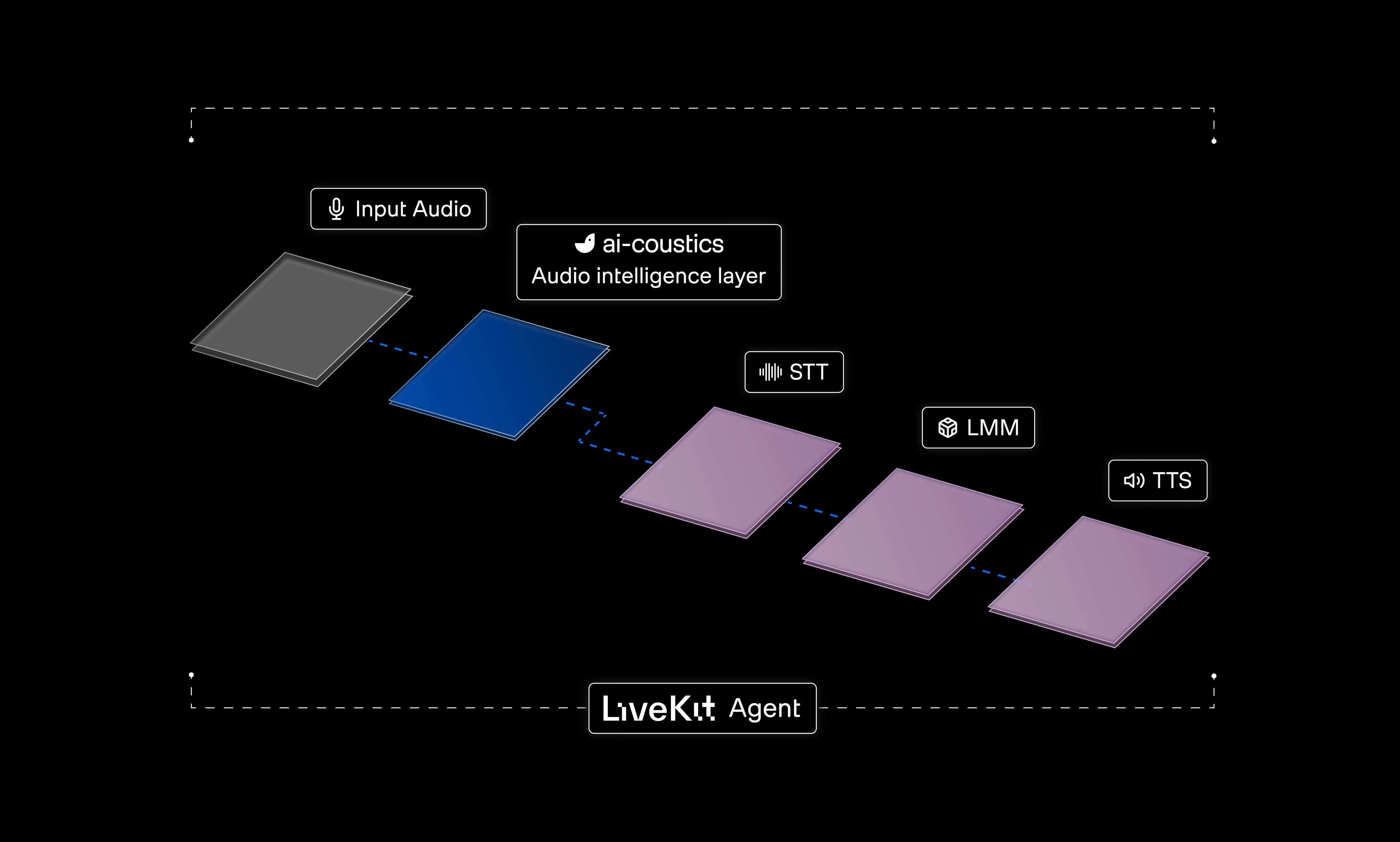
By stabilizing the input layer, ai-coustics strengthens everything downstream. For teams building with LiveKit, that means:
No background voice interference: Voice Focus 2.0 ensures the agent responds to the right person, not the TV or coworker in the background.
Integrated VAD: Combine speech enhancement and main speaker voice activity detection in one module.
Better ASR reliability: Trained to preserve phonetic detail, not strip it. A safer default than perceptual enhancers for production pipelines.

Test the new model today
Quail Voice Focus 2.0 is available now in the ai-coustics SDK. Try it for free, read the benchmark of Voice Focus 2.0, or use it with any custom framework, LiveKit, or Pipecat. You can also talk to the team to get started.
