
Written by
Tim Janke
,
Head of Machine Learning
Product
/
Introduction
Voice has become a primary interface for interacting with software. Modern voice agents rely on cascaded architectures: audio is captured, optionally preprocessed, transcribed by an automatic speech recognition (ASR) system, interpreted by a language model, and rendered back to the user through speech synthesis. End-to-end Speech-to-Speech systems are emerging, but cascaded pipelines remain the dominant production architecture.
In both of these systems, reliability is determined upstream. Once corrupted audio reaches the ASR or language model, errors propagate through the stack which affects intent recognition, turn-taking, and overall user experience.
One of the most persistent failure modes in real-world deployments is interfering speech. Background speakers, media playback, or device echo from the agent itself can:
Destabilize voice activity detection (VAD) and turn-taking (think long pauses or repeated agent interruptions)
Trigger unintended transcriptions
Inject incorrect context into the language model
Decrease overall conversational reliability
Quail Voice Focus 2.0 (QVF 2.0) addresses this problem directly by providing audio based foreground speaker isolation. It is optimized for near-field, single-primary-speaker interactions and designed to suppress competing speech, media playback, and echo before audio reaches downstream systems. In production evaluations, QVF 2.0 reduces Word Error Rates (WER) substantially while improving VAD stability and conversational flow.
In the remainder of this deep dive, we will:
Examine how voice agent pipelines operate and where they fail
Describe how we trained QVF 2.0 using highly realistic, semi-synthetic data
Present quantitative benchmark results for ASR and VAD performance based on a new open evaluation data set
Explain how the enhancement level parameter allows developers to tune insertion–deletion trade-offs for their specific stack
Voice agents that hear too much
Voice AI systems can fail for many reasons, language modeling errors, latency, intent misclassification, or backend instability. However, in production deployments a significant portion of failures originate much earlier in the pipeline: at the audio input layer.
Audio quality directly constrains everything that follows.
Traditional speech enhancement systems are optimized for perceptual quality. Their objective is to make audio sound cleaner to human listeners. For conferencing, media applications, or broadcast processing, this is the correct optimization target.
For voice AI systems perceptual quality is irrelevant. ASR-optimized speech enhancement is required. These systems are trained to improve recognition performance under noise, distortion, and adverse channel conditions. They focus on isolating all voices, denoising, and repairing degradations to improve transcription accuracy. This is the appropriate tool for meeting transcription or smart-device interaction in noisy environments.
Voice agents introduce a further constraint. Agents are typically designed for one-to-one interactive conversations over landlines, mobile phones, or headsets. In this setting, the objective shifts from “cleaner speech” to something more specific: isolating the primary speaker.
Most voice agents do not fail because they cannot hear. They fail because they hear too much. AI systems can't differentiate voices based on audio cues like humans do and situations that wouldn't cause too much trouble in a conversation between humans are breaking the flow in machine interactions. Common real-world scenarios include:
A TV playing in the background, whose speech is transcribed as user input
The agent’s own synthesized voice being captured by the microphone as echo
A secondary speaker across the room entering the transcript
Overlapping speech from nearby conversations
These signals are intelligible speech, just not the speech the system should transcribe.
In these cases, the VAD and ASR models are not malfunctioning. They are doing exactly what they were designed to do: flag and transcribe intelligible speech. The failure arises from passing the wrong speech to the system in the first place.
Foreground speaker isolation addresses this gap. It requires deciding which speech to keep and which to delete. That decision directly affects transcription accuracy, turn-taking stability, and conversational flow.
How we built Quail Voice Focus 2.0
Foreground isolation is a selection problem under acoustic ambiguity. The system must determine which voice belongs to the primary speaker and which does not. Foreground speech must remain intact while interfering speech, echo, and background activity are attenuated without introducing artifacts.
The primary driver of reliable behavior is the training data. QVF 2.0 is trained as a full speech enhancement system, i.e., denoising remains a core objective, while explicitly structuring training data around voice agent failure modes. The optimization target is downstream performance rather than perceptual quality.
Instead of relying on generic augmentation, we generate millions of acoustically structured scenes and digital signal chains that reflect real capture conditions.
Training mixtures combine:
Near-field primary speech
Competing speakers at controlled spatial configurations
Media-device-like speech with realistic spectral characteristics
Stationary and dynamic environmental noise
Echo-aligned playback signals
Simulation of different microphones
Digital artifacts like distortion, codec compression, and packet loss
Room acoustics are modeled using physics-based impulse response simulation, enabling control over spatial geometry and source placement. This allows precise variation of distance-dependent cues and multi-source interactions during training.
Training QVF 2.0 with these highly realistic semi-synthetic training data ensures that suppression behavior remains stable under real-world variability.
Benchmarking
The Dawn Chorus dataset
To analyze the effect of Quail VF 2.0 quantitatively, we will use the Dawn Chorus dataset we are open sourcing together with this release. Dawn Chorus is a data set we created specifically to evaluate foreground speaker isolation. It contains 450 challenging real-world recordings of foreground speakers and competing background speech as well as noise. For each example the clean foreground speaker audio as well as the transcript is available. Please visit the Hugging Face page for more information on how we created Dawn Chorus.
The Word Error Rate
We measure ASR performance using the Word Error Rate (WER). This metric is composed of substitution, insertions, and deletion. Each error type highlights a different weakness in a speech-to-text system, offering insight into why mistakes occur, not just how many:
Substitutions
A substitution happens when the model recognizes that a word was spoken but outputs the wrong one. For example, transcribing “meeting” as “eating”. These errors typically stem from phonetic overlap: background noise, echo or competing speech smudge the acoustic detail, leading the model to confuse similar-sounding words.
Insertions
An insertion occurs when the model adds a word that never appeared in the audio. For instance, converting “Turn left here” into “Turn left right here”. Insertions often signal a tendency of the ASR model to hallucinate: the model relies too heavily on linguistic patterns when the audio is unclear, filling gaps based on expectation rather than evidence. Another common source of insertions is when words get picked up from interfering speakers or media devices running in the background.
Deletions
A deletion is when the model omits a spoken word altogether, for example, turning “The package arrived today” into “The package arrived”. These errors often occur when parts of the signal are obscured by noise such as wind bursts, clipping or microphone bumps. Models with weaker noise resilience prefer to drop uncertain words rather than attempt a guess.
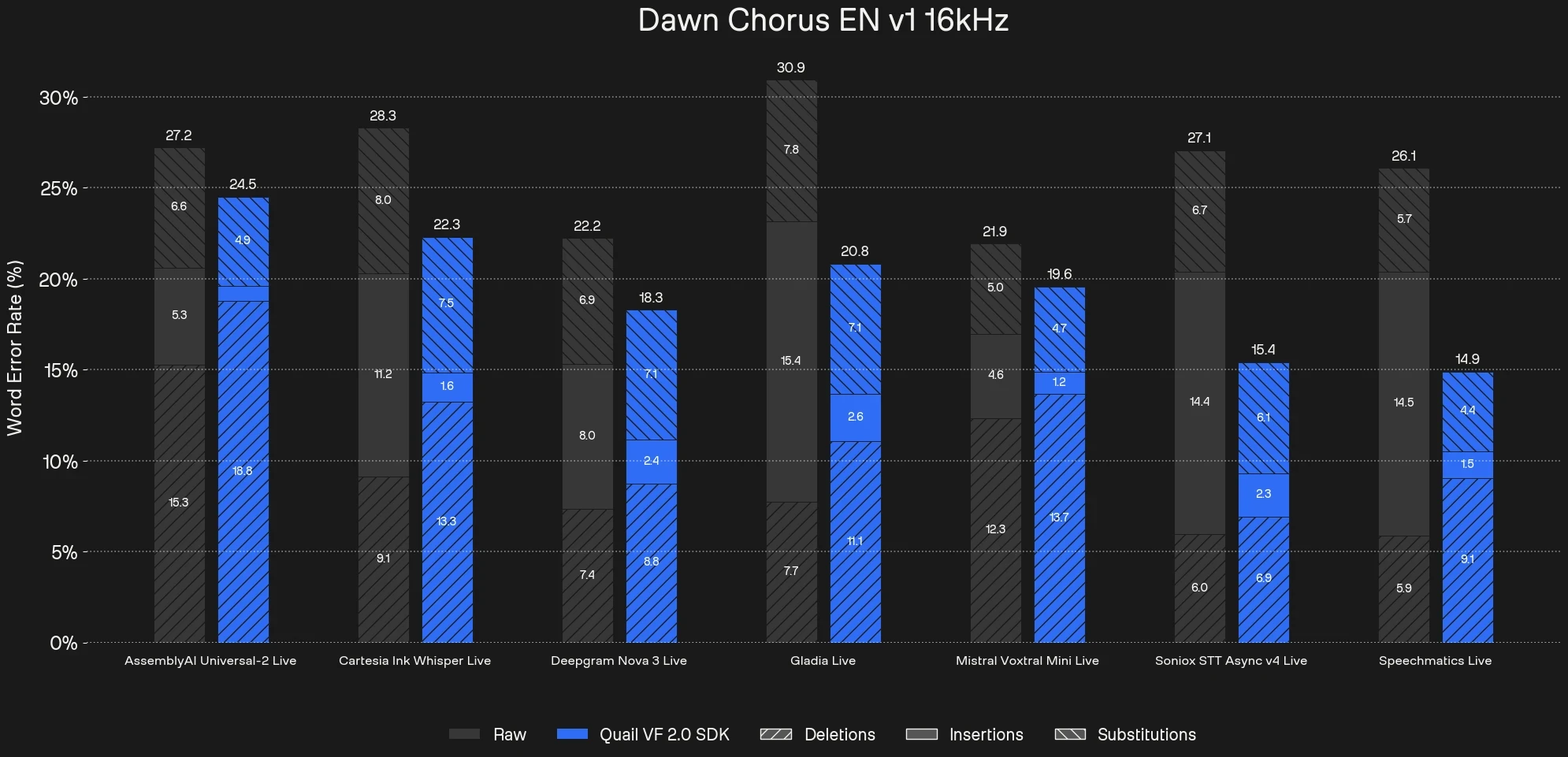
ASR performance
To measure the quantitative impact of Voice Focus we transcribed the raw unprocessed audio as well as the audio pre-processed with Voice Focus with common commercial Speech-to-Text APIs. Across the different ASR providers, the raw audio input produces WER between 21.9% and 30.9%. Especially the insertions account for a large share of the total WER. Pre-processing with Voice Focus reduces the WER on the Dawn Chorus data set across all commercial APIs up to 43%. We can see that this is mainly a result of heavily reduced insertions while substitutions and deletions remain relatively stable.
VAD performance
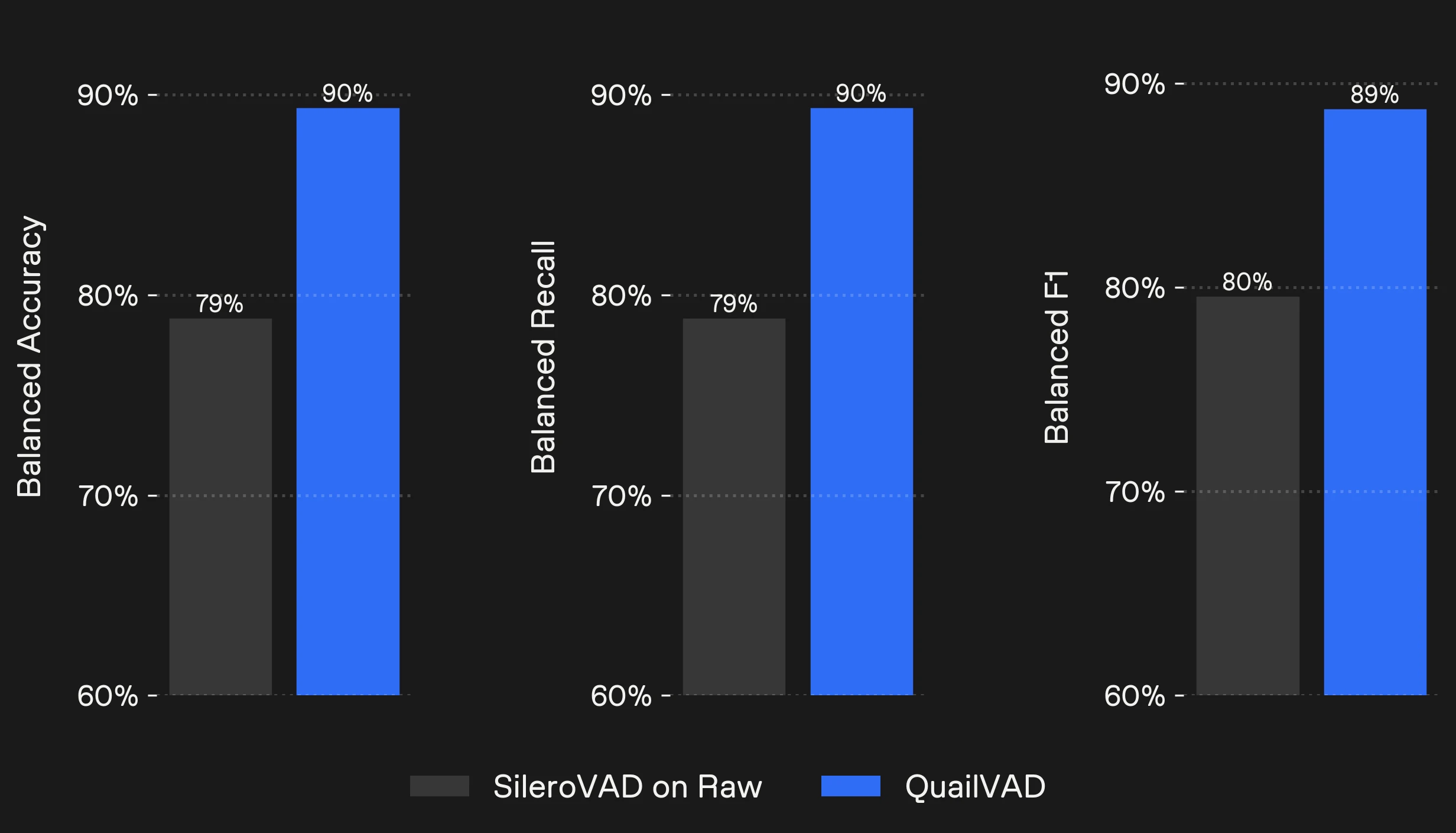
QVF 2.0 comes with an integrated VAD model which you can run at nearly zero additional computational overhead. It is also possible to use the classic Silero VAD after pre-processing with Voice Focus.
On Dawn Chorus Voice Focus VAD improves balanced accuracy from 79% to 90% compared to running SileroVAD on the raw audio. This is mainly due to heavily reduced false positives which are a result of interfering background speakers. This will drastically improve turn-taking and conversation flow.
Qualitative Examples
Tuning the enhancement level to your stack
Different ASR systems and production stacks behave differently under messy real-world audio. As shown earlier, commercial providers vary significantly in how they handle competing speech. Language models, end-pointing logic, and transport layers introduce further variability.
There is no single operating point that is optimal across all stacks.
QVF 2.0 exposes suppression strength through an enhancement level parameter, allowing developers to tune the system for their specific deployment environment and preferred user experience.
The model incorporates a probabilistic component that estimates the confidence of its foreground isolation decisions. This internal confidence signal is used to modulate suppression behavior. Higher enhancement levels shift the system toward stricter decisions under uncertainty; lower levels bias toward preserving ambiguous speech.
At lower enhancement levels, suppression is cautious. Foreground speech is always preserved, minimizing deletion risk but allowing more background leakage.
At higher enhancement levels, suppression becomes stricter. Competing speech and echo are attenuated more aggressively, reducing insertions while increasing the risk of deleting low-energy or uncertain foreground speech.
It is worth noting that even at the maximum level, some noise and reverberation remains in the output. That is because the Quail models are designed to enhance the performance of ASR systems, and may not always produce the most natural-sounding audio for human listeners. If your primary goal is to improve the listening experience for humans, we recommend using our Rook models instead.
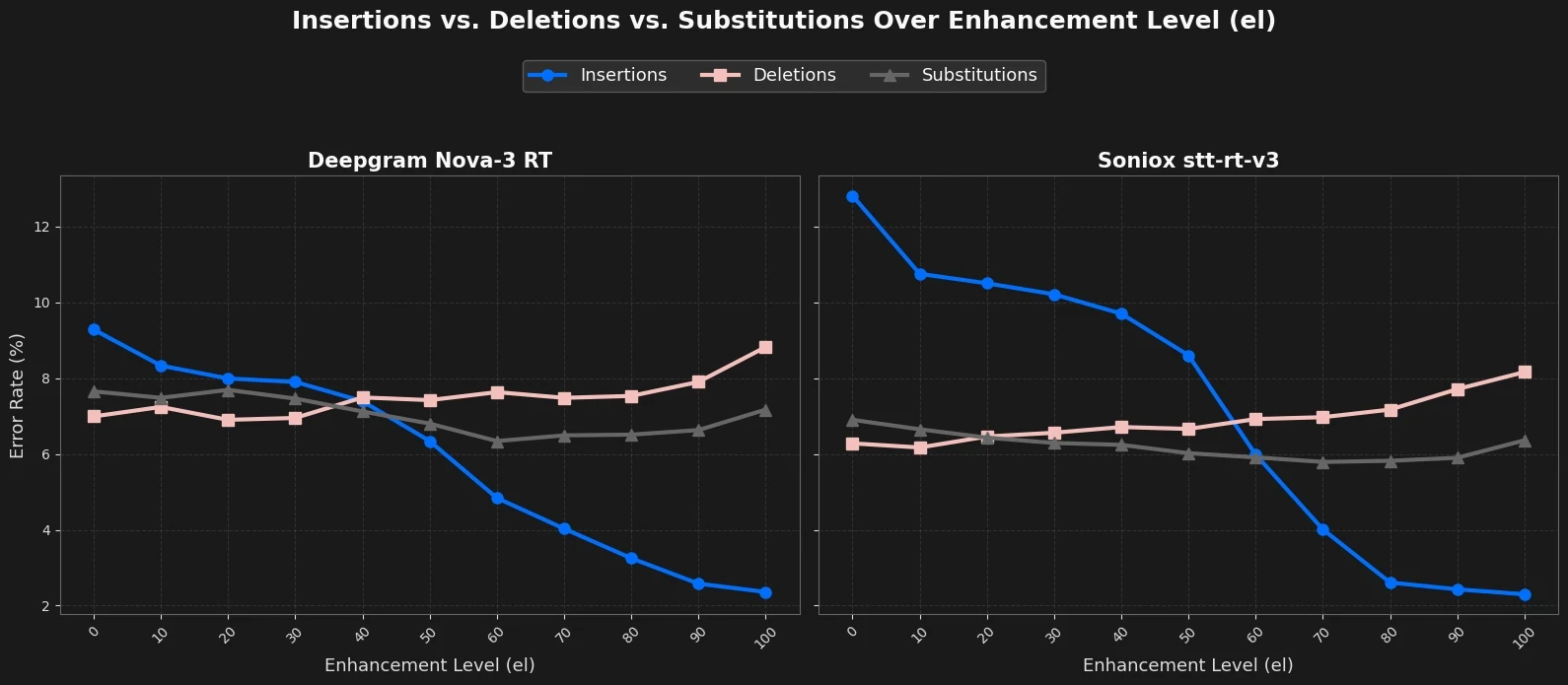
This is also visible when sweeping over the enhancement level and plotting insertions and deletions.
Across enhancement levels:
Insertions decrease steadily.
Deletions increase steadily.
Substitutions remain comparatively stable.
Total WER therefore follows a characteristic U-shaped curve with a deployment-specific optimum. However, lowest WER might not actually represent the optimal operating point in terms of customer satisfaction. Unintended foreground speaker deletion is usually worse for customer experience than insertions from background speech.
We see that the Soniox model tends to transcribe more background speech so higher enhancement level above 60% are optimal. For the less sensitive Deepgram model, values around 50% already represent a solid tradeoff. What becomes clear is that the optimal setting depends on the ASR backend and in a production setting on many other components in your stack.
Foreground isolation under uncertainty is not binary. The enhancement level makes that uncertainty explicit and controllable.
Test the new model today
Quail Voice Focus 2.0 is available now in the ai-coustics SDK. Try it for free, or get in touch with the team. Or head straight to LiveKit, Pipecat or other voice agent platform to start building.
