
Key Takeaways
- ai-coustics and ElevenLabs offer distinct strengths: While both companies operate in the Voice AI space, ai-coustics specializes in ethical, high-fidelity audio enhancement, while ElevenLabs focuses more broadly on voice generation and cloning technologies.
- Choose the right tool for your needs: ai-coustics is ideal for users looking to preserve and enhance real voices with reconstructive AI, whereas ElevenLabs is suited for those seeking advanced synthetic voice capabilities like dubbing and voice cloning.
- Audio enhancement approaches differ: ai-coustics uses reconstructive AI to clean and restore audio without fabricating new content, while ElevenLabs applies generative AI to isolate voices.
Voice AI is an exciting space, and whether you’re a small company or a large corporation there are plenty of ways to integrate it in your workflows. From automating and improving audio engineering processes, to upgrading products with studio-quality audio in every device, the opportunities are endless. But with so many products out there on the market, how do you know what’s right for you? In our new series, we compare a range of popular voice AI products against ours.
ElevenLabs vs ai-coustics: Which audio enhancement tech suits your needs?
Here at ai-coustics, we specialize in enhancing existing audio recordings and real-time streaming. Our reconstructive AI transforms subpar audio into studio-quality sound by eliminating background noise, reducing echo, and improving speech clarity. This makes it particularly valuable for developers, broadcasters, podcasters and more seeking to elevate the audio quality of their content, applications or devices.
ElevenLabs, on the other hand, offers a larger suite of AI audio tools. While it does provide audio enhancement via the ElevenLabs Voice Isolator, its standout features lie in AI voice generation, including text-to-speech, voice cloning, and dubbing. This positions ElevenLabs as a go-to platform for creators aiming to generate lifelike synthetic voices for various applications.
How is ai-coustics different from ElevenLabs?
1. We preserve speaker integrity
Unlike our voice cloning cousins in the Voice AI vertical, here at ai-coustics we never change, edit, or tamper with a speaker’s voice – or what they’re saying. Our reconstructive AI works to protect and preserve the original timbre, accent and sound of every individual voice, and we don’t create ‘new’ voices. That means that there is a level of authenticity and trust at the heart of our robust audio enhancement.
On the other hand, ElevenLabs’s flagship product features voice cloning. While this might be useful for content creators, it does come with a range of troubling ethical implications.
2. We specialize in audio enhancement
ElevenLabs offers a suite of tools including speech-to-text, transcription, voice cloning and voice design, along with audio enhancement. On the other hand, here at ai-coustics we currently focus solely on AI-powered audio enhancement.
For users seeking to access a range of products connected to voice AI including speech-to-text and voice cloning, ElevenLabs may be a better fit. For those focused on the best in AI-powered audio enhancement, ai-coustics have a dedicated and specialist product.
3. We use reconstructive AI
Both ElevenLabs and ai-coustics use AI to offer automated, efficient audio enhancement that cuts down on manual workflows and makes it easy for businesses to scale. But we use different types of AI.
ElevenLabs’ model is built on generative AI, a model type which can produce text, images, videos, or other forms of data based on machine learning and predictions from the database it’s trained on. Whereas at ai-coustics…
What is reconstructive AI?
At ai-coustics, we use a model of generative AI that we call reconstructive AI, which can parse any signal and separate out its threads. For example, it can take an audio recording and distinguish a human voice in an interview, the rumble of traffic, someone else talking in the background and the echo of room resonance. Then it removes everything except the first and most important signal: your interviewee speaking. If there are points where the signal gets too mixed (i.e. a car horn over your interviewee’s voice), it can reconstruct exactly what your interviewee was saying in their own voice.
Reconstructive AI is less prone to audio hallucinations and it also ensures that you’re not making up new content – you’re preserving and enhancing what is already there.
That means if you’re concerned about the ethical ramifications of generative AI or if you’re working in a space which purely requires existing audio to be made perfect, ai-coustics is a better fit.
How does ai-coustics and ElevenLabs’ audio enhancement compare?
Let’s compare ai-coustics and ElevenLabs on this key product to find out how well each product can create studio-quality audio. We’ll start with poor quality sound situations and see (listen!) how both ai-coustics’ and ElevenLab’s technology deal with it.
For these comparisons, we used our Lark model, which is built with reconstructive AI and is available in our API, and coming soon in our SDK.
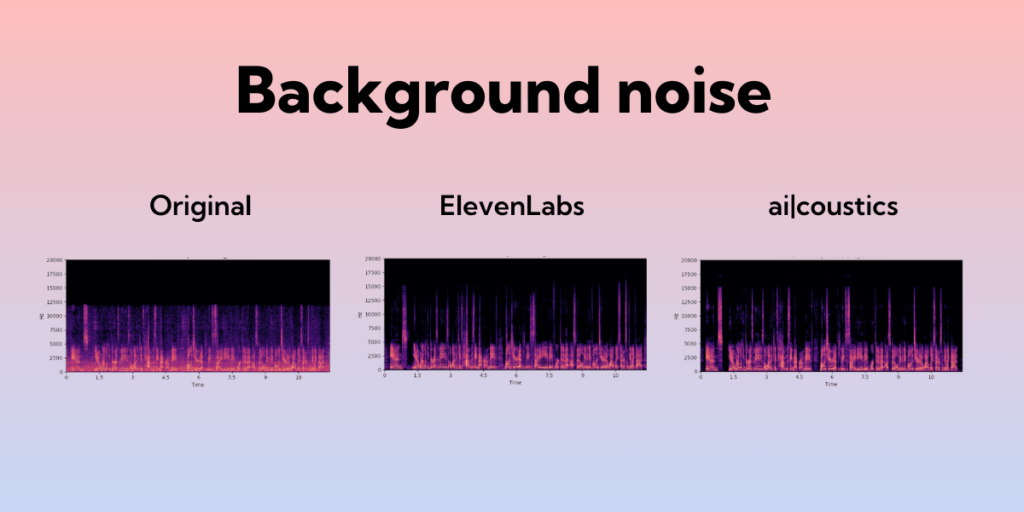
Background noise
The original sample here is an interesting example of a bandlimited voice with sporadic clipping and noise in the background. When we run the sample through the ElevenLabs Voice Isolator tool, the background noise is mostly removed — but it retains the clipping and adds some additional reverb around the voice. The ai-coustics sample, on the other hand, uses our Lark model to remove background noise completely, improve the bandwidth, repair the clipping, and eliminate any remaining reverb. The result is a cleaner, ‘rounder’ sound
ORIGINAL:
ElevenLabs:
ai-coustics:
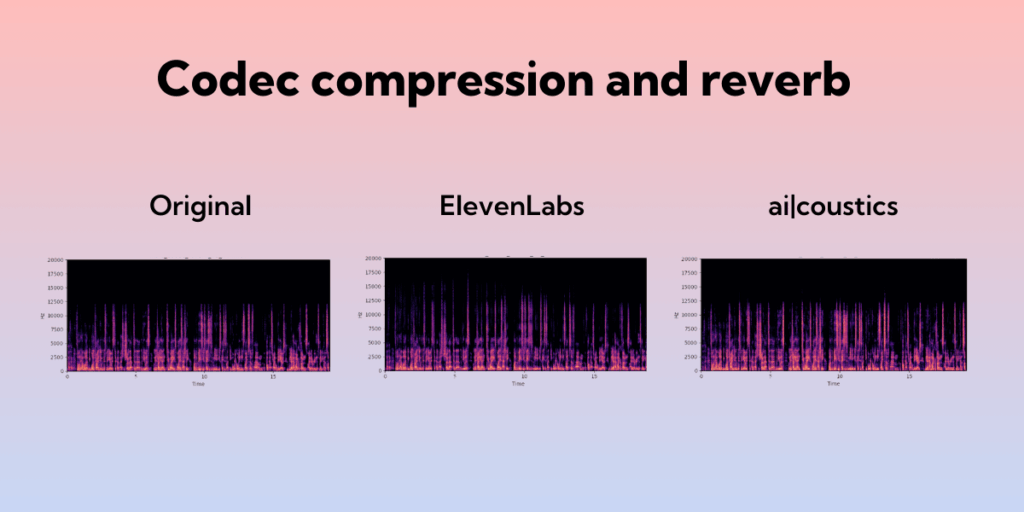
Codec compression and reverb
The original sample here is a typical example of poor sound transmitted over the web or recorded in a poor environment, with strong codec/compression and some reverb. The ElevenLabs Voice Isolator is able to remove some but not all of the compression and reverb. ai-coustics’ Lark model removes even more of the compression and reverb, while also bringing more warmth to the speech’s fundamental frequencies, creating a more pleasant final effect.
ORIGINAL:
ElevenLabs:
ai-coustics:
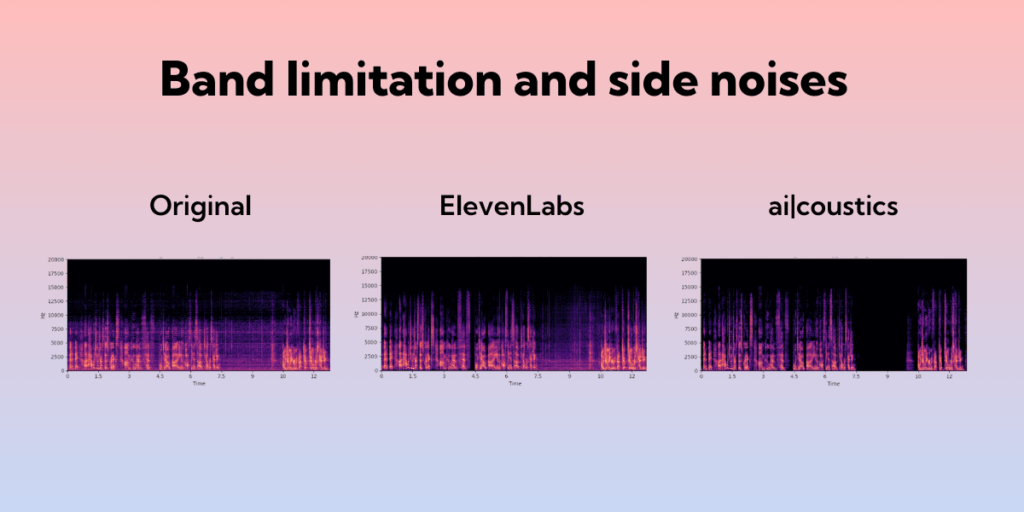
Band limitation and side noises
This sample has band limitation and reverb, along with what some people call “side noises”: background noise which appears between speech and feels like an effect of the technology used to record the speaker. Running the sample through the ElevenLabs Voice Isolator extends the frequency band and reduces the reverb. But it preserves the side noises, and even adds some new audio artefacts of its own. In contrast, ai-coustics extends the frequency range even further, removes reverb, eliminates all background and side noises, and adds warmth and clarity to the voice.
ORIGINAL:
ElevenLabs:
ai-coustics:
So... is ElevenLabs or ai-coustics right for me?
Ultimately, it depends what you’re looking for. While both ai-coustics and ElevenLabs work in the Voice AI space, their core functionalities cater to different needs.
Choose ai-coustics if you want: full-stack AI audio enhancement, accessibility and affordability, transparent performance, a developer-friendly build, an ethical and trustworthy preservation of real human voices, seamless integration, flexibility across deployment types, and optimization for real-time audio enhancement across a wide range of hardware and software.
Choose ElevenLabs if you want: voice cloning, with lifelike synthetic voices for a myriad of applications.
Want to talk more about how we can help your brand achieve studio-quality sound? Get in touch.



