/
Case Study
Speech-to-Text (STT) or Automatic Speech Recognition (ASR) systems perform well in controlled lab conditions, but real-world audio is anything but controlled. Background noise, reverb, accents and low-quality microphones disrupt the acoustic cues these models depend on.
Many teams attempt to fix this with de-noising tools like Krisp, but perceptual enhancement models are built for human ears, not to improve STT/ASR systems. By removing subtle phonetic detail, they often make transcripts less accurate even when the audio sounds cleaner.
On top of that, industry benchmarks like Mozilla Commonvoice or FLEURS often rely on datasets with limited acoustic diversity, which do not mimic the environments real users actually speak in. This mismatch between training data and real-world conditions is a major reason STT pipelines fail in production.
Quail was built to close this gap.
Jump to the benchmark results
Speech enhancement for STT performance
Quail is a new speech enhancement model designed specifically to improve STT accuracy across unpredictable, diverse and challenging environments.
Instead of optimizing for perceptual audio quality, Quail preserves the machine-relevant phonetic structure that STT models rely on – delivering consistent improvements in WER compared to standard de-noising tools as highlighted below.
Example 1
Example 2
Example 3
Example Speech enhancement for STT performance
Example with Raw Audio
Diverse and interesting
but if i were to stick to one
i would combine them
in one breakfast
and it is very delicious
and also it is very nutritious.
Example with Quail
Diverse and interesting
but if i were to stick to one
i would combine them
in one breakfast
and it is very delicious
and also it is very nutritious.
Red means wrong insertions
Transcribed by Gladia
Key benefits of Quail
STT optimized speech enhancement: Reduces noise while preserving timing, articulation and spectral cues essential for accurate STT decoding.
Stronger real-world performance: Proven on diverse, challenging datasets to better reflect real user conditions, while maintaining zero degradation.
Provider agnostic: Improves transcription accuracy across Gladia, Deepgram, AssemblyAI, Cartesia, and more, no model-specific tuning required.
All-in-one SDK: Models for perceptual SE, STT optimized SE and Voice Activity Detection (VAD) – all delivered through a fast, lightweight Rust SDK.
Understanding STT errors: substitutions, insertions and deletions
Before diving into provider-level performance, it’s important to understand three core components of Word Error Rate (WER). Each error type reveals why a model fails - not just how often. In the benchmarks below, the bars are split into three sections:
Substitutions: A substitution occurs when a model hears a word correctly, in timing and structure, but predicts the wrong result. Eg. “coffee” for “copy”. Substitutions are typically caused by phonetic masking - background noise or reverberation blurs acoustic cues, leading the model to misinterpret similar sounding words.
Insertions: An insertion occurs when a model adds a word that wasn’t spoken. Eg. “I’m leaving now” to “I’m actually leaving now”. Insertions reveal a hallucination behavior - the model compensates for unclear audio by relying on contextual expectation. Models that heavily rely on linguistic context are more prone to this when acoustic evidence is weak.
Deletions: A deletion occurs when a model omits a word entirely. Eg. “We live in Berlin” to “We live in”. These are most common when noise masks sections of the speech - like wind, clicks or mic artifacts. Models with weaker noise robustness tend to drop uncertain words instead of guessing.
Provider-level insights: What the benchmarks reveal
With these error modes in mind, we can now examine how today’s commercial transcription engines behave under real-world conditions. The graphs below compare WERs across five major STT providers: Deepgram, Cartesia, Gladia, AssemblyAI and ElevenLabs – on both English (EN) and German (DE) subsets of our internal benchmark dataset.
This dataset was recorded in the wild and contains several hours of audio under challenging real-world conditions, i.e., combinations of diverse noises, rooms, speaker distances, recording devices, and transmission chains. An open-source version of this dataset will be released soon.
Each provider was evaluated with three types of audio preprocessing:
No pre-processing ( i.e., we use the raw noisy audio).
Krisp’s denoiser.
Quail: ai-coustics’ ultra-light real-time SE model optimized for STT.
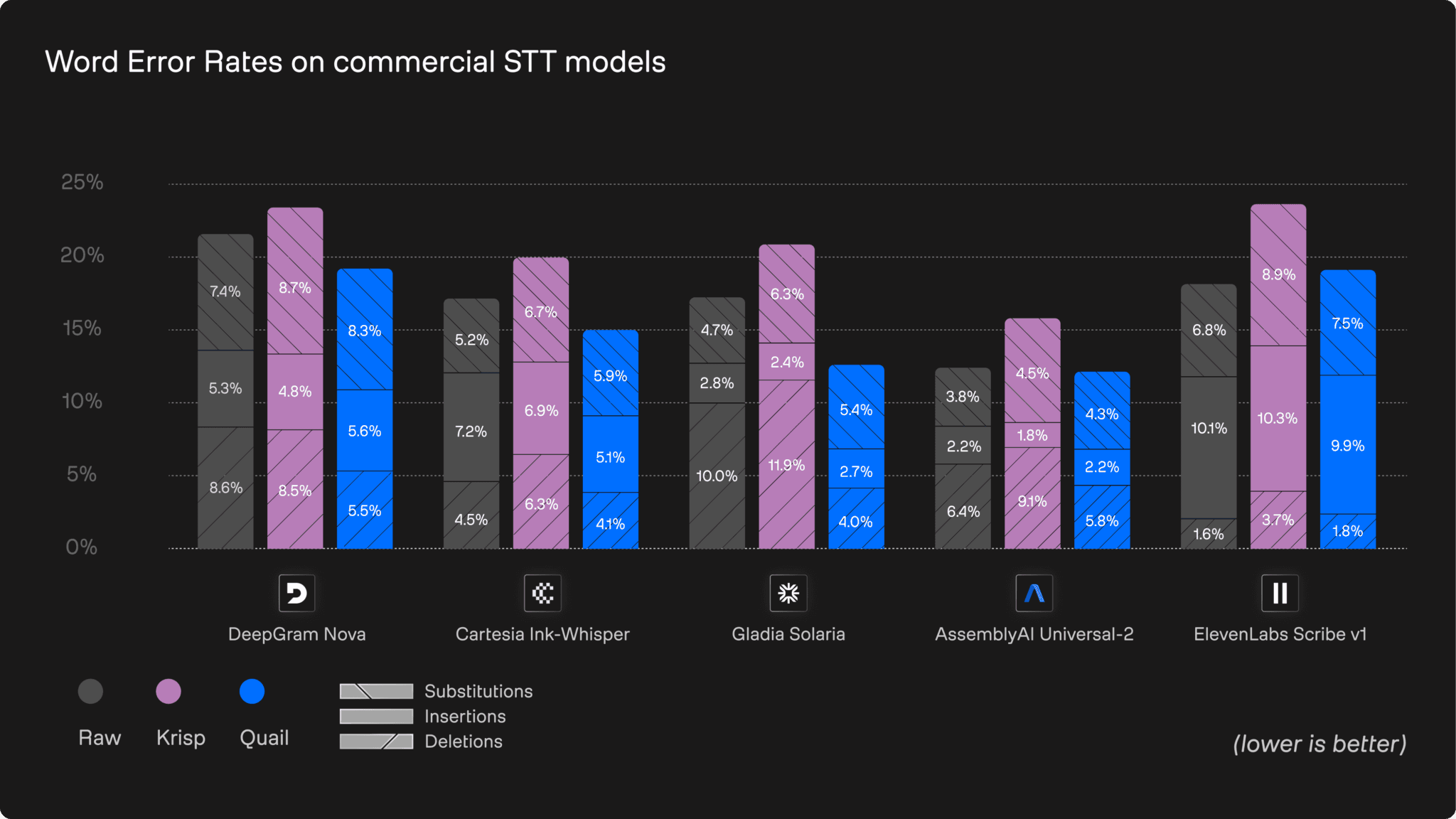
WERs on DE subset
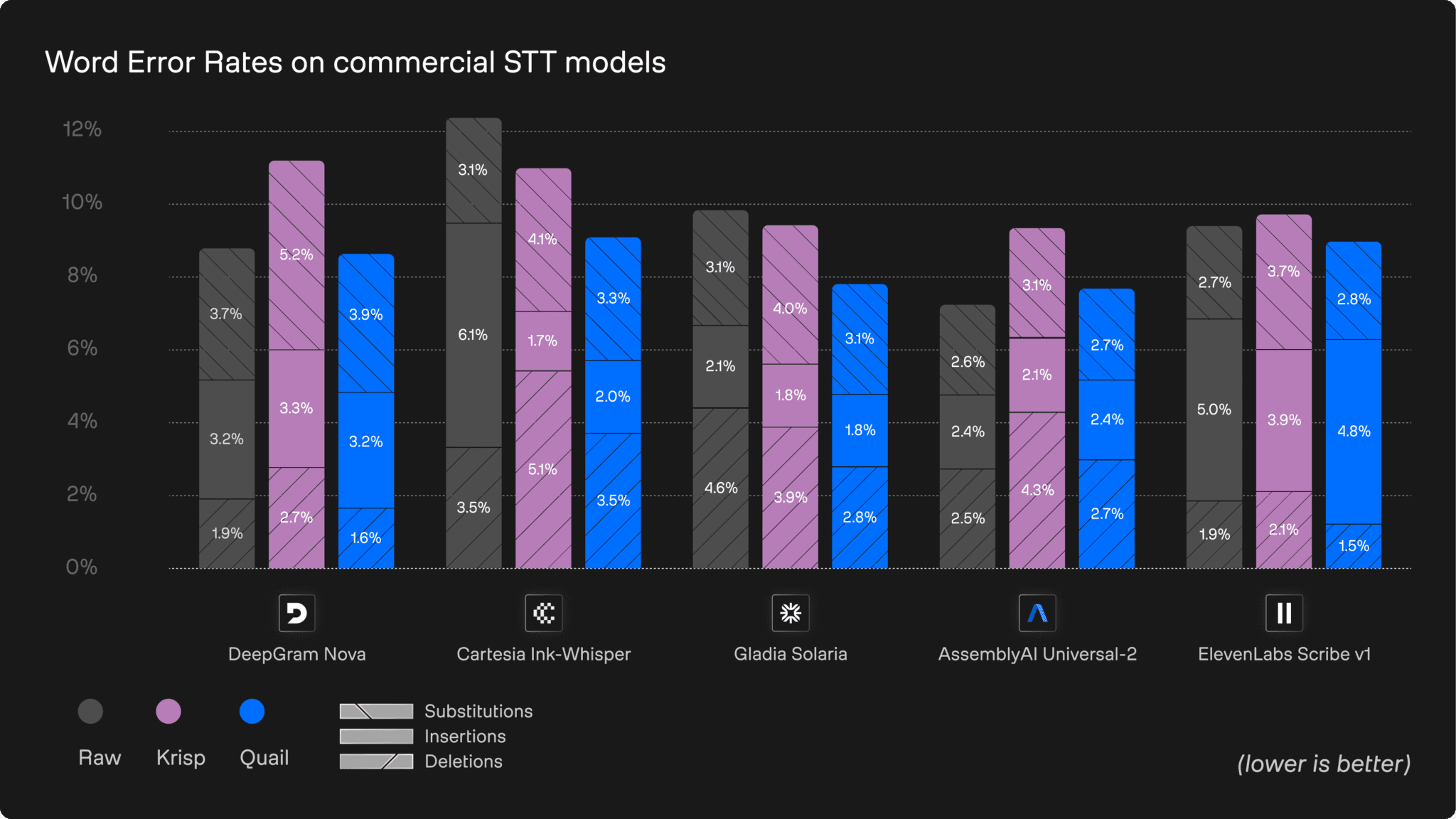
WERs on EN subset
Across STT providers, three clear patterns emerge:
1. Substitution-heavy models
Deepgram and AssemblyAI show the highest proportion of substitutions, particularly in German. Blurred consonants, masked timing cues and oversmoothed detail cause phoneme confusion, leading these models to pick the wrong word rather than hallucinate or drop it.
These substitution-driven errors are a major contributor to the 3-4 percentage point WER reductions Quail delivers on German. Equivalent to a 10–20% drop in total errors.
2. Insertion-prone models
Models that rely strongly on linguistic context (most notably ElevenLabs and to some extent Cartesia) show elevated insertions. When the audio becomes messy, these systems fill gaps with fluent but incorrect words.
Quail reduces these behaviors sharply. In English, insertions fall across all providers, contributing to the 1.5–2.5 percentage point, equivalent to a 15–25% WER reduction.
3. Deletion-focused models
Gladia stands out for its aggressive deletion strategy. Under noisy, challenging or low-quality microphone conditions, it tends to drop entire words when uncertainty spikes.
Quail provides some of the most dramatic improvements here: decreasing WER by 2–3.5 percentage points, representing a 20–30% relative reduction in deletion errors.
The impact of Quail
The combined results highlight a simple pattern: Quail improves accuracy not by cleaning audio for human perception, but by enhancing the machine-relevant structure inside the signal. The benchmark data demonstrates:
Perceptual denoisers often harm transcription: removing noise but also the subtle phonetic information STT/ASR models need.
Quail reduces substitutions, insertions and deletions simultaneously: improving performance regardless of a provider’s error profile.
The biggest gains occur under real-world difficulty: noisy environments, variable accents and low-quality microphones, where STT pipelines usually struggle most.
Clean audio remains unchanged: confirming that Quail is safe to run as an always-on preprocessing layer.
Together, these findings show that Quail is not just another speech enhancement tool – it's an STT-optimized front-end purpose-built to improve transcription accuracy in the unpredictable conditions where it matters most.
Across the English and German datasets, Quail consistently delivers 10–25% relative WER reduction depending on the provider and language – outperforming Krisp by several percentage points on challenging audio.
Try the ai-coustics SDK today
Quail is available now in the ai-coustics SDK. Drop it into your existing pipeline to immediately improve transcription accuracy in real-world environments.
Get in touch for a personalized demo, or sign up to our developer platform to obtain your SDK key. You can then clone or download the SDK code from our GitHub repository to start testing it locally.
Previously:
