
Voice agents are revolutionising the way we interact with technology – but they can only perform as well as the audio they receive.
These systems are built on a complex stack: voice capture, speech recognition (ASR), reasoning (LLMs) and text-to-speech (TTS). While each layer has improved dramatically, one foundational element remains critically underserved and has the potential to break the complete system: the quality of the audio input.
Poor audio leads to missed cues, poorly timed responses and a frustrating user experience. In high-stakes environments like customer service or sales, that frustration can quickly turn into lost trust, increased churn and reduced ROI.
Why audio quality fails
Despite improvements across the voice stack, issues like noise, echo, reverb and compression still persist. This is largely due to constantly varying input conditions, such as users on iPhone in busy places, band-limited landlines or speakerphones in reverberant rooms. These factors impair ASR and VAD, resulting in common failure modes:
Problem 1: Over-transcription
- Cause: VAD picks up background speech as user input
- Impact: Irrelevant transcriptions, agent interruptions
- Example: Chatter in a café is falsely detected by VAD and agent is interrupted
Problem 2: Under-transcription
- Cause: Missed short/quiet user responses due to noise or low SNR
- Impact: Repeated prompts, stalled conversation
- Example: A short “yes” goes undetected, causing agent loops
Problem 3: Turn-taking errors
- Cause: VAD misdetects speech boundaries
- Impact: Agent responds too early or too late
- Example: Agent cuts off the user or delays response due to background noise
ai-coustics SDK: built for voice agent pipelines
The ai-coustics SDK enhances real-time audio input for voice agents, optimizing speech clarity and VAD performance across environments.
- Fast integration via Rust-based SDK with our proprietary AirTen audio inference engine (no ONNX runtime required)
- SDK wrappers available for Python, Node.js, Rust, and C++
- Down to 10ms latency
- Flexible deployment on CPU, optimized for low-latency and cost efficiency
- CPU-efficient and fully compatible with edge and server deployments (1-2% CPU load on single core of Intel Xeon processor)
- Adaptable enhancement strength for manual fine-tuning

Benchmark: improved VAD performance with Quail VAD
Most voice agents use the classic Silero VAD to detect speech and improve conversational flow. We tested the new Quail VAD model against it and found that Quail VAD demonstrates superior performance across key metrics.
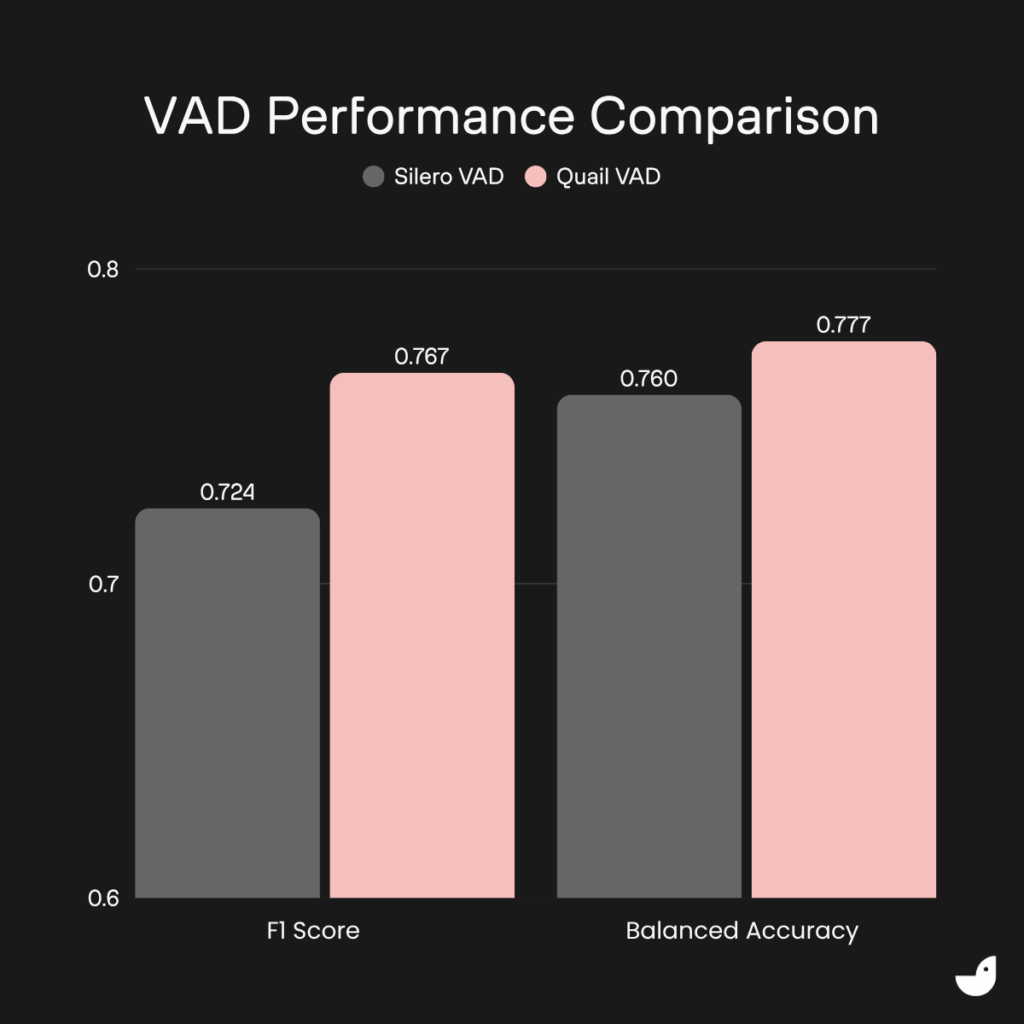
We used the MSDWild dataset, which features realistic acoustic conditions and high background noise, to provide a challenging and representative benchmark for voice agent applications. Across both F1 Score and Balanced Accuracy amongst other important metrics, Quail VAD consistently outperformed Silero. You can read more in our dedicated Quail VAD technical blog.
How does Quail VAD improve your voice agent?
- Increased ASR quality, which improves your voice agent’s recognition and reduces false transcriptions.
- Improved turn-taking, with better conversational timing and speaker transitions across your system.
- A lightweight performance, as Quail VAD is designed to run efficiently with only a minimal processing overhead.
Benchmark: Best-in-class transcription with Quail
Speech-to-Text (STT) or Automatic Speech Recognition (ASR) systems are crucial for the overall performance of your voice agent, but easily scrambled by real-world acoustic challenges, like a busy café or train station. Many teams try to improve their STT processes with de-noising tools like Krisp, but these solutions are built for human ears, not to improve STT/ASR systems. In fact, sometimes Krisp and other de-noising solutions remove subtle phonetic detail which makes transcripts less accurate, even when they sound cleaner.
Quail addresses these challenges with a STT solution specifically designed for real time streaming situations in complex audio environments. Rather than optimizing for perceptual audio quality (a “vibes” check), Quail preserves the machine-relevant phonetic structure that STT models rely on. As a result, it delivers consistently higher improvements in WER.
Take a look at Quail versus Krisp with five major STT providers: Deepgram, Cartesia, Gladia, AssemblyAI and ElevenLabs.
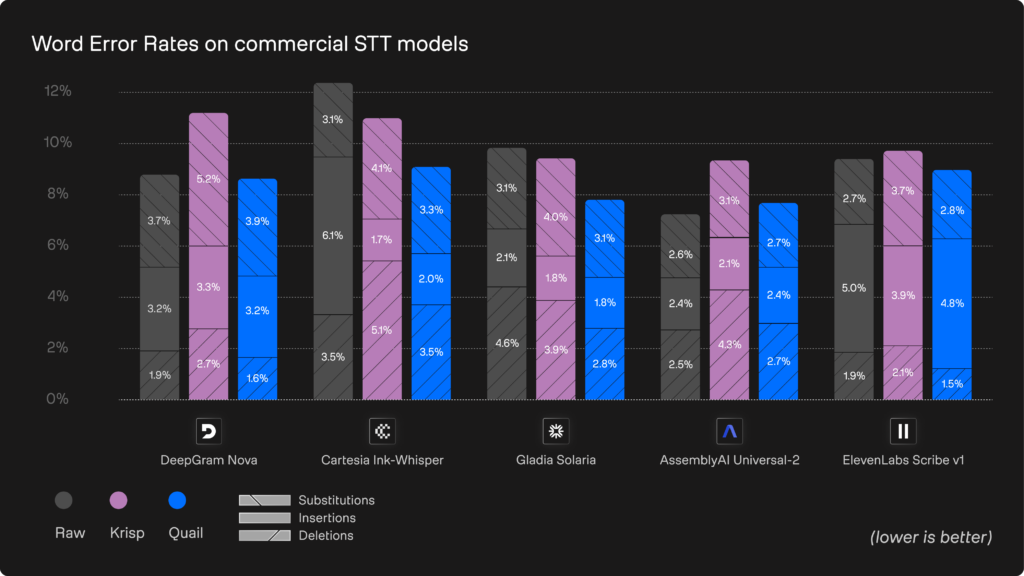
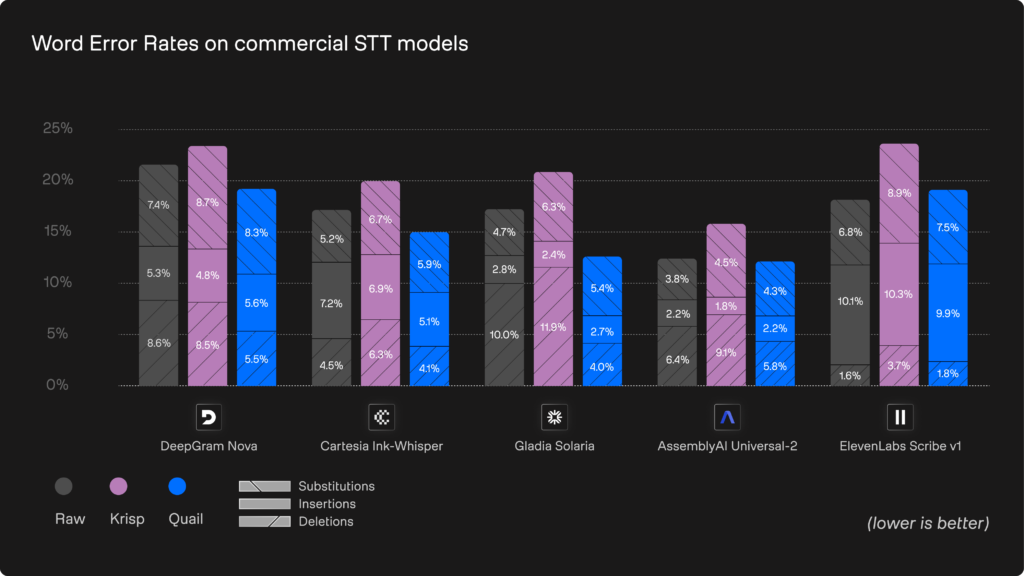
You can read the full technical breakdown of these benchmarks in our dedicated Quail blog, but key takeaways include:
- 10-30% drop in total errors across various providers and systems
- Best-in-class performance against standard STT providers as a standalone and a de-noising solution from Krisp
- Biggest gains in complex real world situations, like noisy environments, variable accents, and low-quality microphones, where STT pipelines usually struggle most
How does Quail STT improve your voice agent?
- Provider agnostic, reducing substitutions, insertions and deletions, regardless of your STT provider.
- 10-25% reduction in Word Error Rate, for a higher performing voice agent.
- All-in-one audio enhancement, with VAD, STT and perpetual SE all delivered through one fast, lightweight Rust SDK.
We're now integrated in Pipecat:
The Pipecat integration lets teams build voice agents that directly interact with live data and APIs. This enables real-time context, automation, and smarter responses within conversations, making agents more production-ready from the start.
Learn more in the filter overview here on Pipecat.
What’s next
Our SDK, complete with Quail, Quail Voice Focus and Quail VAD, is available to test free in our developer portal. Sign up to the developer portal to generate your SDK key and start testing today. Check out our tutorial video for a guide on getting started.
We’re curious to learn more about challenges in the voice agent input layer. If you’re building in that space, we’d love to hear from you, feel free to book a call with our founder here.



